- v1.0.0-latest-prod
|
Important
|
Data Feeds functionality is in a pre-release stage and not generally available. The functionality as well as this documentation is subject to change. |
Conceptually, data feeds are a mechanism through which data from one system is sent to another system.
In eCommerce applications, the primary use-case is for 'product data feeds', where the focus is on transferring product information. Common systems accepting product data feeds include price comparison engines and product ad platforms. For example, Google Merchant Center ingests product data feeds to list products across Google services.
Broadleaf Data Feed Services contains all key functionality required to successfully gather data from Broadleaf systems and publish it using data feeds to external systems.
There are two main types of data feed processes by default: FULL_AUTHORITATIVE and PARTIAL_UPDATE.
FULL_AUTHORITATIVE processes are responsible for uploading the full authoritative dataset of all entries that belong in a feed.
Third parties typically refer to this type of feed as a 'full' or 'primary' feed, where the end-result of submission is a full replacement of the dataset such that it exactly matches the contents of the upload.
For example, with a feed file approach, this typically means the destination will create any items from the file that it hasn’t seen before. If the destination currently has an item that is not present in the file, it will be deleted.
PARTIAL_UPDATE processes are exclusively responsible for updating existing entries in a data feed rather than creating or removing entries.
Third parties typically refer to this type of feed as a 'supplementary' feed or an 'update' process.
Typically, destinations allow higher frequencies of these types of updates as compared to FULL_AUTHORITATIVE.
Different feed destinations have different limitations on what can be achieved with a partial update - some support 'upserts' and 'deletes' in supplementary feeds, while others don’t. However, almost all destinations do support updating fields on existing entities (ex: stock availability, price changes) with this mechanism.
|
Note
|
See the shared concept documentation for more on partial processes. |
In Broadleaf, the overall feed process flow remains highly similar between full and partial jobs. The main difference lies in how partial update jobs determine which entities to include in the collection and publication process.
Data feed jobs are comprised of a few different key concepts.
|
Tip
|
See the data model documentation for how these concepts are persisted in the data store. |
DataFeedProcessThis is an admin-manageable 'template' configuration for a job that will perform a single query for data and then publish that data to one or more data feeds.
DataFeedProcessExecutionThis tracks the lifecycle and state of a specific execution of a DataFeedProcess.
The system (not admin users) manages the entire lifecycle of these entities.
DataFeedPublicationThis represents a 'sub-execution' within a DataFeedProcessExecution that is specifically interested in transforming data (which was already fetched in an earlier step of the execution) and publishing it for one specific DataFeedPublicationConfiguration.
The system (not admin users) manages the entire lifecycle of these entities.
DataFeedPublicationConfigurationTo publish data to a particular data feed (regardless of the destination), there are unique secret values (ex: API keys) and configuration that are required but cannot be persisted in a datastore.
These need to be managed separately via application properties and environment variables by system administrators, and thus cannot be directly part of the admin-user configured/persisted DataFeedProcess entity.
DataFeedPublicationConfiguration represents a non-persisted, identifiable abstraction of an individual data feed publication configuration. DataFeedProcess can subsequently reference specific configurations that will be included in its flow.
The knowledge of how to use a particular DataFeedPublicationConfiguration requires a compatible DataFeedPublisher implementation.
Details on how these instances are constructed are provided in the publication configuration design docs.
It is important to note that despite the name, this is not related in any way to the Spring @Configuration concept.
IncrementalDataFeedEntityUpdateRecordEach IncrementalDataFeedEntityUpdateRecord contains key reference details about an entity that was updated elsewhere in Broadleaf, and now deserves re-processing to keep data feed(s) up to date.
For each IncrementalDataFeedEntityUpdateEvent that is received from other Broadleaf microservices, an IncrementalDataFeedEntityUpdateRecord will be created for each DataFeedProcess of type PARTIAL_UPDATE who may be interested in processing it.
This means each PARTIAL_UPDATE DataFeedProcess will effectively have its own 'queue' of update events that it can process whenever it is executed.
|
Note
|
See the shared concept documentation for a detailed look at how IncrementalDataFeedEntityUpdateRecord instances are created.
|
The system (not admin users) manages the entire lifecycle of these entities.
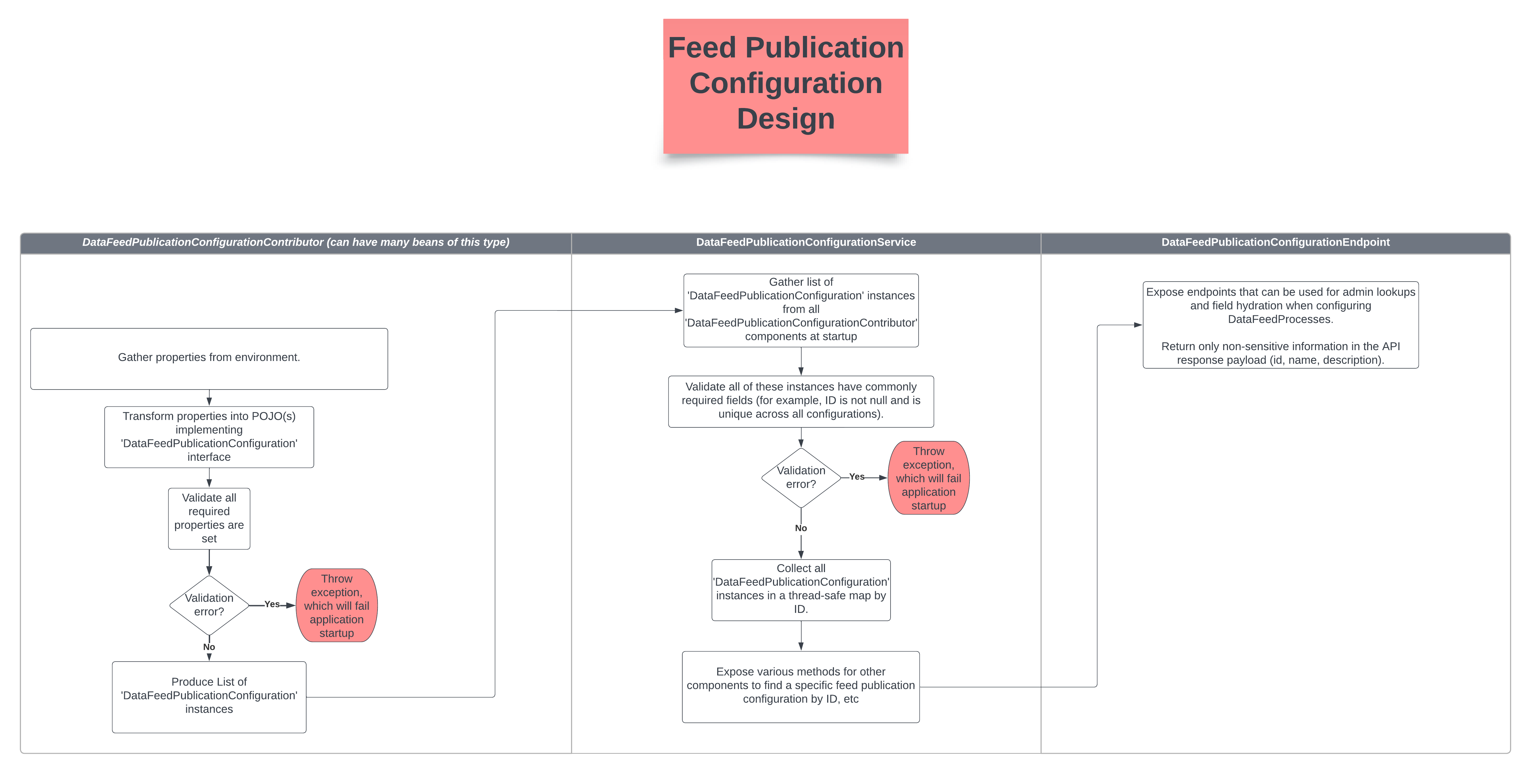
The mechanism to establish DataFeedPublicationConfiguration instances is outlined below.
Configuration properties under a known prefix are gathered to define behavior for a particular publication process
Example:
MerchantCenterSFTPConfigurationProperties
DataFeedPublicationConfigurationContributor beans transform gathered property values into DataFeedPublicationConfiguration instances
Example:
MerchantCenterSFTPPublicationConfigurationContributor, which produces MerchantCenterSFTPPublicationConfiguration instances
At startup, DataFeedPublicationConfigurationService injects and invokes all DataFeedPublicationConfigurationContributor components to collect all DataFeedPublicationConfiguration instances in one place for centralized access by other components
In the Broadleaf Admin, admin users can create new 'full' or 'partial' data feed processes under Processes > Data Feeds > Data Feed Processes.
|
Tip
|
If possible, try to maximize the number of publication configurations on each DataFeedProcess.
For example, if you need to publish a primary feed for the same data from 'Application X' to both Google Merchant Center and Meta Commerce Manager, try to put both of those publication configurations on the same DataFeedProcess rather than creating separate DataFeedProcess instances for each.
This way, the data collection process (potentially expensive) is only run once and the collected data can be shared by both publication steps.
|
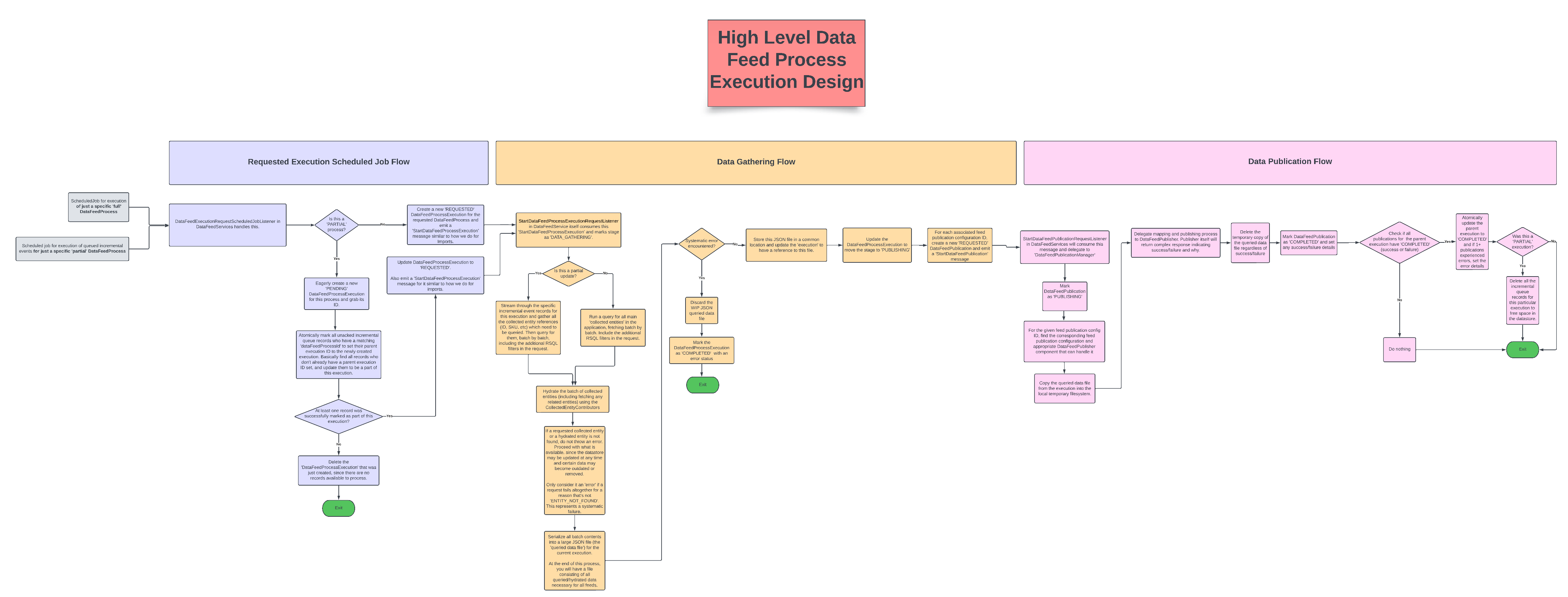
Executing any given DataFeedProcess is done through scheduled jobs owned by Scheduled-Job Services.
In the Broadleaf Admin, managing scheduled jobs for data feeds is made easy under Processes > Data Feeds > Data Feed Process Execution Schedules.
Besides standard recurring execution, admins can also manually run a process by clicking the 3-dot icon in the top right corner and selecting 'Run Now'.
Scheduled job trigger events are received by DataFeedExecutionRequestScheduledJobListener, which delegates to DataFeedProcessExecutionManager to request an execution for the specified DataFeedProcess.
For 'full' processes, DataFeedProcessExecutionManager will create a new DataFeedProcessExecution and emit a StartDataFeedProcessExecutionRequest message
For 'partial' processes, DataFeedProcessExecutionManager will create a new DataFeedProcessExecution.
Then, it will gather all unacked IncrementalDataFeedEntityUpdateRecord entries for the specified process and mark them as part of the newly created execution (effectively 'acking' them).
If at least one IncrementalDataFeedEntityUpdateRecord was successfully found and acked for this process, the DataFeedProcessExecution is advanced to the next stage and a StartDataFeedProcessExecutionRequest message is emitted
StartDataFeedProcessExecutionRequestListener in Data Feed Services itself will consume the emitted StartDataFeedProcessExecutionRequest message and delegate to DataFeedProcessExecutionManager to actually run the specified execution
Collecting data is the first step in running a DataFeedProcessExecution.
The DataFeedProcessExecutionManager delegates to the first compatible DataFeedCollector component that can handle collection for the execution.
The goal of the DataFeedCollector is to gather data from Broadleaf systems, ultimately producing a file containing the collected data.
Besides gathering entities of the base collected type, implementations of DataFeedCollector may further delegate to CollectedEntityContributor implementations to hydrate additional data onto each collected entity.
For example, ProductDataFeedCollector gathers products from CatalogServices, and then additionally hydrates inventory, pricing, and reviews information on each CollectedProduct through InventoryEntityContributor, PricingEntityContributor, and RatingsReviewsEntityContributor.
Furthermore, since ProductDataFeedCollector is an extension of AbstractJsonArrayDataFeedCollector, the file it builds is ultimately just an array of JSON objects, with each element representing a CollectedProduct.
|
Note
|
The data collection step is the only time any querying or API requests should occur. Any data required by the transformation steps should be gathered and set onto each collected entity in this stage. The expectation is that transformation of any specific collected entity to an output representation only requires data already present on the collected entity. |
Between the 'full' and 'partial' process types, the overall collection/contribution mechanism is the same. The main difference lies in the determination of which base collected entities need to be fetched.
Full process executions are typically interested in gathering 'all data' within a particular application.
This is typically achieved by performing sorted, paginated requests for batches of the collected entity, then applying CollectedEntityContributors to those batches.
Each final hydrated batch is then serialized to the file.
Partial process executions are only interested in collecting specific entities referenced by the IncrementalDataFeedEntityUpdateRecords currently being processed.
This first requires gathering all the different IncrementalDataFeedEntityUpdateRecord references and building up a distinct set of entity IDs to process.
For example, given a mix of SKUs, external IDs, and IDs, DataFeedServices should make requests as needed to ultimately end up with a final set of IDs that it will process.
Then, typically that ID set is broken into batches for collection.
For example, DataFeedServices would send CatalogServices a request to get 25 products by ID.
The received batch of collected products would then go through the CollectedEntityContributors for additional hydration.
Each final hydrated batch is then serialized to the file.
The DataFeedCollector will usually prepare its output file in a temporary local filesystem directory.
After collection is complete, the DataFeedProcessExecutionManager copies the data from the file to a more long-lived, commonly accessible location via the StorageService.
The default implementation of StorageService is JpaDataFeedFileLobStorageService, which leverages LOB storage in the database to hold the file data.
The 'location' of this data (by default, just the unique filename used by the StorageService for the file) is updated on the DataFeedProcessExecution for downstream consumption.
Publication encompasses the end-to-end flow of iterating over the collected entities, transforming them into the representation needed by the feed destination, and submitting the final result.
After collection is complete and the data file is properly stored, DataFeedProcessExecutionManager will engage the publication step.
For better performance and status tracking, publication for each destination is broken out into its own sub-execution called a DataFeedPublication.
DataFeedProcessExecutionManager creates a new DataFeedPublication and emits a StartDataFeedPublicationRequest for each DataFeedPublicationConfiguration referenced by the DataFeedProcessExecution.
StartDataFeedPublicationRequestListener consumes each of these messages and delegates to DataFeedPublicationManager to run each publication.
This has good workload distribution characteristics, as different instances of DataFeedServices can process the publications in parallel.
DataFeedPublicationManager first reaches out to StorageService and reads the contents of the collected data file into a temporary file on the local filesystem.
Afterwards, it delegates to the first compatible DataFeedPublisher implementation to actually execute the publication steps.
The goal of the DataFeedPublisher is to actually perform the end-to-end read-transform-submit flow.
|
Note
|
In some cases, publication for 'partial' and 'full' processes may be similar enough that the same DataFeedPublisher can handle both.
|
There are a variety of ways a feed destination may accept data, but one of the most common is through feed file uploads. With file-based approaches, the destination expects data to be serialized to a file (typically standard formats like CSV or XML) and then uploaded either through an API call or an SFTP transfer.
By default, Broadleaf DataFeedServices provides AbstractFileFeedPublisher as a robust starting point for file-based implementations.
Internally, AbstractFileFeedPublisher delegates to a few other components:
DataFeedFileTransformer
Responsible for reading through the collected data file, transforming collected entities to the output representation, and serializing the result to a final output file.
By default, AbstractJsonArrayToCSVFileTransformer and AbstractJsonArrayToXMLFileTransformer provide useful starting points for transforming a JSON array collected data file into CSV and XML output, respectively.
Internally, each of these delegate to a few other components:
StreamingJsonArrayFileReader
A utility for streaming over the collected data file, deserializing the collected elements into POJOs in batches, and performing arbitrary work on each batch.
DataFeedElementTransformer
|
Note
|
In almost all cases, this is the component that will involve the most customization to match unique business requirements. |
Responsible for converting a batch of collected entity POJOs into POJO elements of output data.
The expectation is for the output POJO to be defined and configured in a way that can easily be serialized to a file via utilities such as Jackson’s CsvMapper or XmlMapper.
For example, this could mean using special Jackson annotations and mapper configuration to define property names and serialization behavior.
See MerchantCenterXMLProduct as an example of what’s done for Google Merchant Center.
After each batch of elements is successfully converted, it is immediately serialized to the output file.
DataFeedFileSubmitter
Responsible for taking a transformed output file and submitting it to the destination.
This typically involves gathering configuration details such as authentication credentials from the DataFeedPublicationConfiguration to prepare and execute the submission.
By default, AbstractSFTPSubmitter is provided as a useful starting point for implementations that need to use SFTP for file submission.
After completing a DataFeedPublication, DataFeedPublicationManager checks to see if all publications for the associated DataFeedProcessExecution are also completed.
If so, it delegates to DataFeedProcessExecutionManager to engage completion of the DataFeedProcessExecution.
First, the execution is marked as completed with any necessary status details.
Then, if the execution was for a 'partial' process, any IncrementalDataFeedEntityUpdateRecords for that execution are hard-deleted to free space in the data store.
Out of box, Data Feed Services comes with integrations to a few different platforms.
DataFeedServices supports submitting XML-file-based product feeds over SFTP to Google Merchant Center for both primary and supplementary feeds.
| Name | Description | Default |
|---|---|---|
|
Whether to enable Merchant Center related functionality. |
|
|
Properties configuring a specific Merchant Center publication configuration.
Note that the publication configuration ID should always be all-caps (ex: 'MY_ID') to ensure Spring relaxed property binding sees the same value no matter where the properties are being sourced from.
See |
Create your 'Upload' type primary feed (for 'full' processes) and/or supplementary feed (for 'partial processes') by following the Google feed creation documentation
|
Note
|
At this time, the official Google 'Regional product inventory feeds' functionality is not automatically supported out of box. (Customizations should be able to adjust functionality as needed.) By default, the expectation is for each Merchant Center 'sub account' to be for a specific locale, with its primary and supplementary feeds only having translations/pricing for that locale. For example, if you had data for Egypt and wanted to support English and Arabic, you would create 2 separate Merchant Center sub accounts - Egypt English and Egypt Arabic, and then primary and supplementary feeds for each sub account (4 total feeds). |
Note down the unique filename you specified for this feed.
Obtain SFTP credentials as described in Google feed SFTP documentation
Establish a new feed publication configuration for each feed (ex: MY_MERCHANT_CENTER_FULL_CONFIG_ID) by setting properties under broadleaf.datafeed.feedprovider.google.sftp.configs.MY_MERCHANT_CENTER_FULL_CONFIG_ID.*
Provide the unique filename and SFTP credentials from previous steps
Create a new DataFeedProcess that targets your new feed publication configuration and execute it
If the default implementation doesn’t quite satisfy your business needs, you can customize the behavior.
In almost all cases, the only customization needed will be in the behavior of CollectedProductToMerchantCenterXMLProductTransformer, where Broadleaf collected entities are transformed into output elements.
Please examine the logic of this component and override its behavior as needed.
DataFeedServices supports submitting CSV-file-based product feeds through API requests to Meta Commerce Manager for both primary and supplementary feeds.
| Name | Description | Default |
|---|---|---|
|
Whether to enable Commerce Manager related functionality. |
|
|
Properties configuring a specific Commerce Manager publication configuration.
Note that the publication configuration ID should always be all-caps (ex: 'MY_ID') to ensure Spring relaxed property binding sees the same value no matter where the properties are being sourced from.
See |
Create a new Facebook business account, following Facebook documentation
Create a new Facebook Commerce Manager account, following Facebook documentation
Create a new product catalog and corresponding feed configuration
Facebook feed creation documentation
|
Note
|
Choose the 'Upload from computer' approach for creating feeds. DataFeedServices will be pushing data to Facebook with direct API upload requests - it will not be hosting feed files at a URL. |
|
Note
|
At this time, the official Facebook 'Country and language feeds' functionality is not automatically supported out of box. (Customizations should be able to adjust functionality as needed.) By default, the expectation is for each Facebook product catalog to be for a specific locale, with its primary and supplementary feeds only having translations/pricing for that locale. For example, if you had data for Egypt and wanted to support English and Arabic, you would create 2 separate Facebook product catalogs - Egypt English and Egypt Arabic, and then primary and supplementary feeds for each catalog (4 total feeds). |
After creating a feed, note down the data feed ID. This is available in the Commerce Manager UI under 'Catalog > Data Sources > Data feeds'.
Create a permanent, non-expiring access token with permissions capable of controlling the commerce catalog associated with the data feed. This is necessary for DataFeedServices to make API requests to upload feed files.
To create such an access token, you first create a Meta developer application and associate it with the business account.
Then, in business settings, a System User must be created.
Then, on the system user page, access tokens can be granted (option for permanent here) with the selected permissions.
In this case, the catalog_management scope should be granted.
|
Tip
|
You can debug your access token and verify it is correct with the Facebook Access Token Debugger. |
Establish a new feed publication configuration for each feed (ex: MY_COMMERCE_MANAGER_FULL_CONFIG_ID) by setting properties under
broadleaf.datafeed.feedprovider.meta.api.configs.MY_COMMERCE_MANAGER_FULL_CONFIG_ID.*
Provide the data feed ID and access token from previous steps
Create a new DataFeedProcess that targets your new feed publication configuration and execute it
If the default implementation doesn’t quite satisfy your business needs, you can customize the behavior.
In almost all cases, the only customization needed will be in the behavior of CollectedProductToCommerceManagerFeedCSVProductTransformer, where Broadleaf collected entities are transformed into output elements.
Please examine the logic of this component and override its behavior as needed.