- v1.0.0-latest-prod
The Broadleaf Import Services provides overall process management and acceptance of flat-files (like a CSV or Excel sheet) of data being distributed downstream to different components via a message broker.
|
Note
|
See the shared concept documentation for a higher-level overview. |
'Specifications' are the way to define different types of imports. Each specification describes all the details about a particular import type that ImportServices needs to know.
At a high level, specifications describe both what a user of the import is expected to provide in their request/file, and how to transform that input into something the corresponding resource-tier handler will expect. Thus, despite being in different microservices, specifications and resource tier handlers have fairly tight coupling and work together to provide a complete implementation of a particular import. It’s recommended to also provide an example import file for each implementation as a reference point for users.
Key specification items include:
The 'type' of the import itself, which is a distinct value specifications and resource tier batch handlers use to understand whether they apply to a particular import implementation.
For example, you can decide to have an import type MY_SPECIAL_IMPORT that imports entity X and entity Y.
Then, you would introduce a corresponding specification and resource tier handler that both declare MY_SPECIAL_IMPORT as the import type they support/implement.
The security scopes and authorities (permissions) required to perform the import. This is described further below.
What headers to accept in the original file, as well as how to map each user-friendly header (ex: 'Product Name') to a backend-friendly field that the resource-tier handler is expecting (ex: 'name')
Allowed row-types and their expected hierarchy - this is used to understand which rows should be considered 'dependents' of others
Imports have 'main records', which are rows of the 'main' type being imported (ex: for a product import, it’d be product). However, some import types may also have 'dependent records', which are rows intended to be children of the 'main' row type they are defined under (ex: for a product import, this could be variants). Dependents can themselves also have dependents. The configuration for this is fairly flexible - ultimately, the structure should match what the resource tier handler expects.
Simple, eager validations (such as required header values and type checks) which the import service can perform early without reliance on any resource-tier information
Default values to use for headers that are not provided in each row
Specifications are defined by implementing ImportSpecification - in most cases, DefaultSpecification is a good starting point to extend from.
For each specification that is defined in ImportServices, there should be a corresponding resource-tier ImportBatchHandler implementation.
GlobalImportSpecification is a marker interface typically used to indicate an import specification should be made available as an option in the central 'start import' admin page (vs an import that should only be started elsewhere, such as a specific entity’s grid action)
(since 1.8.1) ImportSpecificationService provides a centralized mechanism for fetching ImportSpecifications based on certain criteria
ImportSpecificationDefining required security scopes and authorities in the ImportSpecification is critically important.
Without these, anyone who has the basic authority to access the /start import endpoint will be able to successfully perform that import.
By defining specific scopes and authorities for your specification, you can ensure, for example, an import related to products will only be successfully submitted if the caller’s authorities also include product-related authorities.
|
Tip
|
It’s typically recommended to define net-new scopes/permissions for your import to maximize the granularity of access control.
For example, rather than just making a product-related import use the standard PRODUCT scope and permissions, create a new IMPORT_PRODUCT scope and permissions (in AuthenticationServices) and then reference those in your specification.
This differentiates who can individually manage products via the admin UI and who can manage them through the import process.
|
While most fields follow the format of single-cell/single-value, in some cases it may be valuable for a particular implementation to accept a complex value structure in a cell to simplify the user experience. For example, it may be preferable to allow users to provide a comma-separated list in a cell value to define a collection field.
As mentioned before, the only requirement is for the specification and resource-tier handler to be in agreement about the structure of the data. Thus, so long as this is true, implementations can define their own syntax and expectations as they please.
However, the import consumer common library does provide a handful of basic delimiters and utilities to support complex-value use-cases (see RowUtils).
Some out-of-box implementations already leverage this functionality and can serve as a reference for usage.
(emphasized since 1.8.1)
When developing a new import implementation, try to avoid having a single, highly complex import specification/handler for simultaneously processing creates/updates on multiple types of entities. Instead, create separate, dedicated specifications and handlers tailored for their intended use-case.
This greatly reduces the complexity of each implementation, improving maintainability and avoiding the pitfalls of a 'one size fits all' solution, which will inevitably run into edge cases.
|
Note
|
In some cases (such as a complex product import), the needs for a multi-entity, multi-operation type import may warrant the complexity. However, it’s worthwhile being aware of the tradeoffs documented here. |
For example, it may be tempting to create a single specification/handler where EntityX can be both created and updated.
However, opt instead to define a separate specification/handler for creating net new instances of EntityX, and additional specifications/handlers for updating specific fields on EntityX to support common use-cases.
For example, you may have a specification that creates new products in the system, as well as a more granular update specification that only allows updating product prices.
|
Note
|
In some simple cases, it may make sense for there to be separate specifications/import-types that are all handled by the same resource tier handler. This strategy would be most effective in the event that the separate create/update handlers would be highly similar to each other anyway, and thus consolidating into one component would simplify the implementation. |
This comes with a few benefits (not exhaustive):
'Creates' typically require more fields to be supplied by the user than 'updates'. By separating specifications, you can have the 'create' specification define more required fields, and only require key fields you expect in each 'update' specification. This allows better fast-fail behavior at the import service tier rather than delaying validation until the resource tier processes it.
Handler implementations become significantly simpler, since they can more readily expect how to handle errors.
For example, in a 'do-everything' handler, you may opt to create an entity if it does not exist, and update an entity if it exists. If a user accidentally misspelled the ID of an entity they wanted to update, your handler would try to create the entity instead of treating it as a failed update. With separate, dedicated create and update implementations, the handler doesn’t need to guess intent and can correctly fail the update. Furthermore, the user is not burdened with needing to specify any sort of 'operation type' on each row, since it is implicit.
Handlers naturally need to be implemented in a way that supports retries in the event of failed imports. It is much simpler to handle retries when the handler does not also have to be concerned with determining create vs update operation types.
Optimization of field structure
In some cases, it’s possible that the most optimal/user-friendly structure for providing a certain field differs between creates and updates. It’s possible import consumers frequently need to update a specific, complex field in an opinionated manner. It’s also possible that the very same field in a 'create' is auto-generated by the handler rather than accepted as input. Separation of specifications/handlers allows each implementation to more accurately serve the needs of a use-case with greater testability and consistency.
Separated example import files for each implementation make it easier to communicate expectations to end-users
Admin users can initiate imports manually through the admin UI (go to /imports).
|
Note
|
For imports that should automatically happen on a scheduled basis, implementers may define custom scheduled jobs in Broadleaf’s Scheduled-Job Services. |
For each import implementation, it’s important for end users to know what fields and value structures they should be supplying in their files.
ImportServices has the concept of 'Example Imports': pre-written files that demonstrate how a user can supply data. The expectation is for each import implementation to have a corresponding example file defined as a class-path resource. These files are served to users through the admin UI.
|
Tip
|
To maximize the benefit of the example, try to include all headers, any special edge-cases, and any complex value schemas that you think users may want to know. |
ExampleImportManager is the main service component used to fetch examples, and it checks all ExampleImportResolver instances to find the first resource matching the request
UserExampleImportResolver resolves examples from the examples/ resources directory.
To add new examples, clients should typically just add their example files to this directory with the expected name (typically just the lowercase import type) and file extension.
If more complex logic is necessary, clients can also simply define their own new ExampleImportResolver beans.
DefaultExampleImportResolver is intended for serving out-of-box examples provided by Broadleaf in the default-examples/ resources directory.
This is given lowest precedence to allow client configuration to take priority.
Certain imports may be responsible for importing entities under a common 'parent entity'. For example, an import of price data should place all the price data entities in the import under the same parent price list.
To make it easier to support such use-cases without requiring the parent entity information to be supplied in the imported file itself, there is a first-class parentEntityId field accepted in ImportRequest and eventually passed to the resource-tier batch handler through BatchContext.
Ultimately, the usage of this value is entirely determined by the resource tier handler implementation.
(since 1.8.2) ImportSpecification supports marking this parentEntityId field as required in the request
When an import is submitted from an ImportGridAction (admin metadata concept), it will implicitly provide this value in the request.
Since these grid actions are typically only defined in the context of the parent entity’s edit page, the value is automatically sourced from the parent view.
(since 1.8.2) For imports submitted from the admin’s central import maintenance page (as is the case for GlobalImportSpecifications), there is an ImportRequestParentEntityLookupContributor admin metadata concept which makes it easy to define a specialized parent entity lookup field for each specific import type (if applicable).
The lookup value will be used to set parentEntityId in the request.
To get this behavior, simply define a new implementation of ImportRequestParentEntityLookupContributor for your import type, and register this as a bean in the ImportServices metadata configuration.
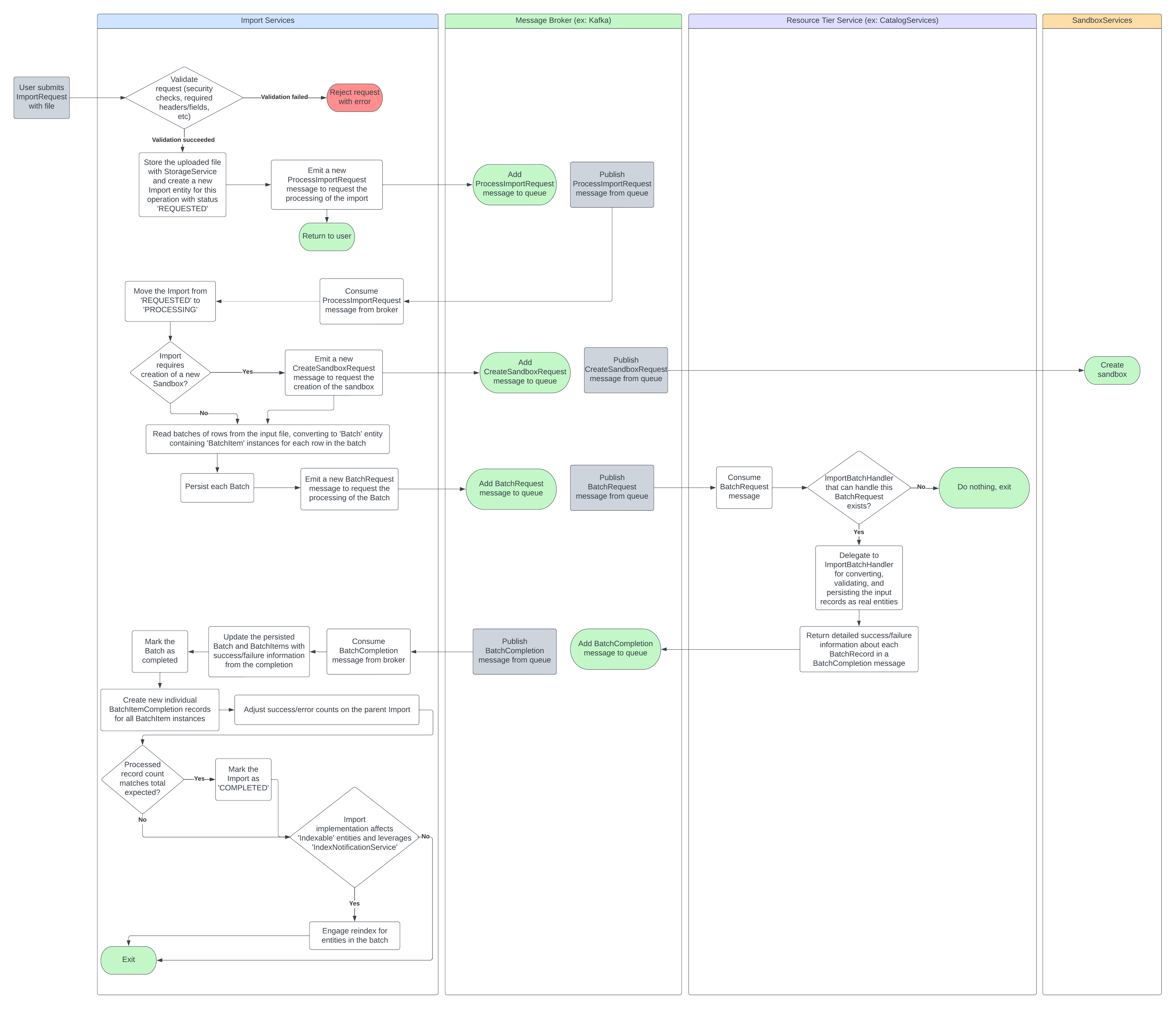
When an import request is received, ImportManager is the top-level component responsible for coordinating key steps in initial processing.
Key operations it performs:
Initialization of the Import instance from the request
Security validations to confirm the requesting user has authorization to access the intended 'importing context' and has the requisite authorities.
Identification of the ImportSpecification, ImportValidator, and FileReader appropriate for the import request
|
Tip
|
See File Type Support documentation for more details on allowed file types. |
Execution of basic validations on the import by delegating to ImportValidator (for example, required headers and field validations)
Storage of the import file by delegating to StorageService
Persistence of the Import in a REQUESTED status after all validations are successful, which will also result in the emission of a ProcessImportRequest to the message broker
Following these steps, the initiation phase is considered complete and will return to the caller.
After the initiation phase persists the Import and publishes ProcessImportRequest, the import service itself will listen for ProcessImportRequest messages via the ProcessImportRequestListener.
|
Note
|
This relies on Broadleaf’s common messaging component IdempotentMessageConsumptionService as well as atomic updates on the persisted Import to guarantee thread-safe idempotent message consumption.
|
This will ultimately call ImportManager, which will begin true processing for the import.
|
Note
|
By moving 'batching' to an asynchronous process via ProcessImportRequest, we ensure the (potentially lengthy) processing of files can happen in the background rather than tying up a request thread.
Furthermore, it opens up the possibility of better load-balancing across instances of ImportServices depending on message consumer configuration.
|
Key operations it performs:
Move the Import from REQUESTED to PROCESSING
For imports that request sandbox creation, emit an IMPORT_CREATE_SANDBOX_REQUEST which should result in Sandbox Services ultimately creating the sandbox
|
Note
|
Import Services does not check for successful sandbox creation - it simply emits the message and proceeds optimistically |
See CreateSandboxRequest and CreateSandboxRequestMessageFactory
Identify the ImportProcessor, ImportSpecification, and FileReader appropriate for the import
Delegate further processing to ImportProcessor (described below)
At a high level, ImportProcessor is responsible for reading through the file and producing/emitting batches for consumption by the resource-tier handler.
The field configuration and behaviors defined in ImportSpecification are used to guide the processor’s behavior for transforming the original input row into what’s expected by the resource-tier handler.
This includes the concepts of 'dependent' records, header-field mappings, default values, eager resource tier ID generation, eager operation type generation, and more.
The number of elements in each batch is determined by the batchSize configured for the ImportProcessor.
Main records and their dependents both count against batch size limits, but since all dependents are always bundled with their parent main record (never broken across batch boundaries), it’s possible that the total number of items in a batch exceeds the limit.
However, the total number of main records in a batch will never exceed batchSize.
For example, let’s say the batch size limit is 2 and the input contains mainRecordA with 3 dependents and mainRecordB with 3 dependents.
Since dependents count, mainRecordA with its dependents (4 total records) will reach the batch size limit and will be considered a separate batch from mainRecordB with its dependents.
For each batch of rows that is read from the file, the following happens:
The individual rows are transformed into BatchRecord instances, where the processed row values will be a Map<String, String>
These are identified by a unique correlationId, which is used to track their success/failure as they go through the import lifecycle
The BatchRecord instances are converted to BatchItem instances and gathered into a Batch instance for persistence
See BatchManager
The Batch is persisted and a BATCH_REQUEST message is emitted over the message broker for consumption by resource tier handlers
See BatchService, BatchRequest, and BatchRequestMessageFactory
Once the whole file is processed and the batch requests are sent, the responsibility shifts to the corresponding resource tier ImportBatchHandler to process the requests and return completion information.
After a resource tier handler processes a batch, it is expected to return a BatchCompletion over the message broker.
This should contain BatchCompletionRecord information describing the success/failure of processing each individually requested batch item.
Import Services will listen for these completions via BatchCompletionListener, and delegate to BatchCompletionService to handle them.
|
Note
|
This relies on Broadleaf’s common messaging component IdempotentMessageConsumptionService as well as atomic updates on the persisted Batch to guarantee thread-safe idempotent message consumption.
|
At a high level, BatchCompletionService does the following:
Updates the persisted Batch and BatchItems with success/failure information from the completion and marks the Batch as completed (delegates to BatchService)
Creates BatchItemCompletion records for all BatchItem instances (delegates to BatchItemCompletionService)
Adjusts the success/error counts on the parent Import, and marks it as COMPLETED if processed count matches total
(if applicable) Notifies the indexer service about all Indexable instances which have been affected (delegates to IndexNotificationService)
The BatchItemCompletion domain is used to surface success/failure about individual rows to the end-user.
If an import (which is not still in-progress) has at least one unsuccessful BatchItemCompletion, users can make a request to download an 'errors report'.
The 'errors report' is intended to match the original file but only include the rows which failed (including dependents as necessary).
In addition, the errors report will include extra headers describing why the row failed.
The expectation is for users to download this report, modify the file to fix any errors, and then submit the file in a new import.
The process of actually building the errors report is done by ErrorsReportService, and the default implementation is CSVErrorsReportService.
Indexable imported entitiesIn some cases, the entities being imported may be Indexable for search purposes.
You will need to consider how to engage 're-index' behavior on those that are successfully persisted (to ensure search data remains current).
Typically, this is done by emitting SingleIndexRequest or BatchIndexRequest messages to request re-index by IndexerServices.
|
Note
|
This would only be relevant for 'production' imports (where entities are not being imported into a sandbox) or for imports into an application sandbox (which support the 'preview changes' feature). |
There are several possible options.
SingleIndexRequest behavior at the resource tierBy default, persistence of an Indexable entity automatically triggers a SingleIndexRequest message to be emitted for it in the resource tier service.
This behavior is a default across Broadleaf and is not an import-specific concept.
|
Note
|
While this may technically work 'out of box', it is inadvisable to rely on this mechanism when potentially large numbers of entities are being persisted (as is the case with import).
The number of SingleIndexRequest messages may cause backups in the message broker queue and take longer to process.
|
IndexNotificationService to emit BatchIndexRequest messages upon receipt of each BatchCompletionAs referenced in the completion handling section, ImportServices itself has very basic functionality in place to support emitting BatchIndexRequest messages upon receipt of a BatchCompletion.
At a high level, the idea is such:
The resource tier ImportBatchHandler#handle() implementation should disable the default SingleIndexRequest emission behavior by using the @SuppressNotification annotation.
@SuppressNotification(SingleIndexRequestProducer.TYPE)
@Override
public BatchCompletion handle(BatchRequest batch) {
// ...
}In ImportServices, when a BatchCompletion is received, IndexNotificationService will emit a BatchIndexRequest for it.
The default implementation in DefaultIndexNotificationService for building the BatchIndexRequest is very simple, as there is very little domain-specific (or import-implementation-specific) information available in ImportServices.
The service iterates through all successful, top-level (not dependent) BatchItemCompletion instances for the given import batch and obtains their resourceTierIdentifier values.
This list is ultimately set on the BatchIndexRequest message as the 'IDs to index'.
DefaultIndexNotificationService has its own logic to determine what to set as the 'batch indexable type' on the BatchIndexRequest message.
(since 1.8.2) DefaultIndexNotificationService injects and leverages ImportBatchIndexableTypeMapping beans to determine the batch indexable type to use for an Import.
For each import type that should participate in this behavior, clients should register their own ImportBatchIndexableTypeMapping beans.
For example, let’s say a client introduces an import of type SPECIAL_PRODUCT_UPDATE which affects products.
They should register a new ImportBatchIndexableTypeMapping that returns PRODUCT as the batch indexable type only if the given Import has type SPECIAL_PRODUCT_UPDATE.
Certain import types already have defaults provided, such as ProductImportBatchIndexableTypeMapping and CustomerImportBatchIndexableTypeMapping.
These beans are ordered with lower priority to give client beans precedence (clients can use Spring’s @Order to order their beans higher).
Prior to 1.8.2, DefaultIndexNotificationService examined the Import#getType() type of the completed batch and would try to exactly match it to a value in the BatchIndexableType enum.
For example, since the PRODUCT import type matched BatchIndexableType.PRODUCT, the behavior would successfully engage.
If a match was not found, index notification would be skipped.
|
Note
|
While this works for various simple cases, it does have limitations. The implementation assumes only the 'top-level entity' (main record) in a particular import will need to have re-index request messages sent out for it, and does not consider possibilities of indexing other entities in the import.
Row based dependents and column-based dependents are not considered - it assumes the Thus, it does not handle the case where separate |
ImportBatchHandler|
Note
|
For complex indexing scenarios, this is likely the best option. |
Given that each resource-tier ImportBatchHandler implementation can vary significantly in behavior, it makes a lot of sense for indexing concerns to be handled there.
Each handler has full knowledge/availability of the involved domains (what is Indexable, what is not) as well as any import-specific implementation quirks.
This means the handler can fully control behavior, potentially even using different indexing approaches (SingleIndexRequest versus BatchIndexRequest) for different entities.
In some scenarios, clients may already expect 'full re-index' jobs to be running on some scheduled basis (ex: nightly) for the imported domain(s).
If immediately re-indexing data after an import is not important, deferring re-indexing concerns to these jobs may be a viable solution.
Clients must consider whether the overhead of a full re-index is acceptable (versus just re-indexing the newly persisted or updated entities).
At the time of this writing, there’s no sandboxable entities in this service. If a sandboxable entity is introduced in this service, the following configurations should be added:
spring:
cloud:
stream:
bindings:
persistenceOutput:
triggeredJobEventInputPurgeSandbox:
group: import-purge-sandbox
destination: triggeredJobEvent
broadleaf:
transitionrequest:
enabled: true
changesummary:
notification:
active: true
tracking:
sandbox:
purge:
enabled: trueSee Sandboxing In Detail for more details.
|
Note
|
These configurations typically only affect the
Granular Deployment model. For Min and Balanced deployements, these configurations are likely already added at the flexpackage-level configuration.
|