- v1.0.0-latest-prod
|
Warning
|
This service is considered EXPERIMENTAL and is not available for general use. An extended commercial license is needed in order to obtain and use this functionality. Please contact a Broadleaf representative for more details |
|
Important
|
The Recommendations Engine is compatible with the 2.2.x Release Trains |
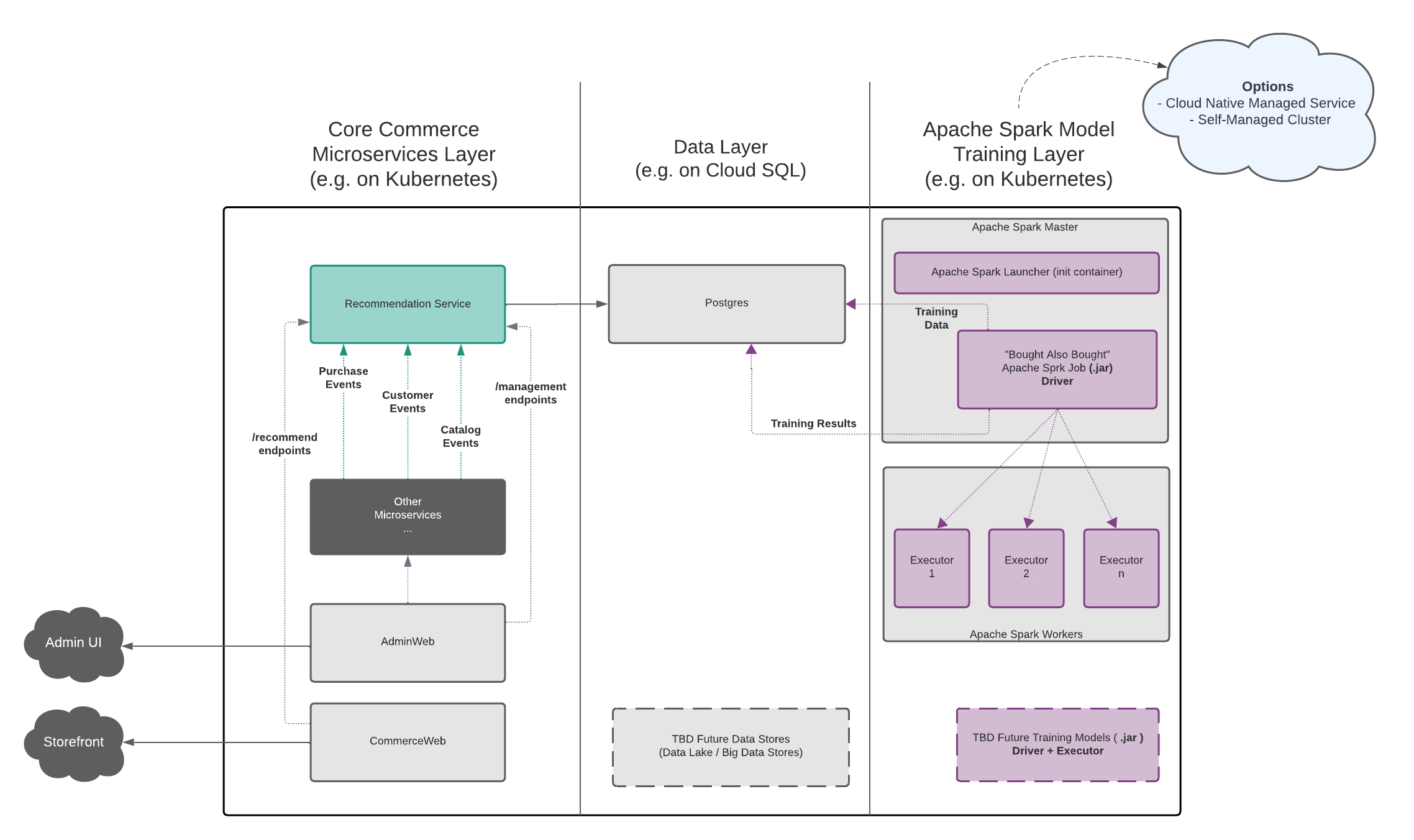
Conceptually, Broadleaf’s Recommendation Engine capabilities can be thought of in 3 distinct "layers":
The core Broadleaf Microservices Layer
The Data Layer
The Model Training Layer (powered by Apache Spark)
The following diagram depicts this in more detail:
this layer consists of the existing Broadleaf Microservices ecosystem such as the Flex Packages (e.g. browse, cart, supporting, etc…) and other supporting applications typically running on Kubernetes
Broadleaf provides an individual "Recommendation Engine" service that is deployed in this layer (typically inside a Flex Package).
This recommendation component contains several listeners and endpoints to facilitate capturing and storing certain events and data points that will be stored in the configured data store.
By default, this Recommendation Engine microservice component will store certain data points into a relational data store following the same patterns as other Flex Packages in the Broadleaf ecosystem. As with the other microservices, the Recommendation engine assumes an isolated bounded context and will persist data into a recommendationengine schema
This data store will also be used by the "Model Training Layer" to store various training results data points which can be queried and utilized by the Recommendation Engine service when needed
Depending on the amount of data points you collect for training, you may want to consider configuring the Recommendation Engine microservice to utilize its own Database (separate from the other Broadleaf microservices, i.e. not just a separate schema) in order to separate and scale this service in isolation and not impact DB resource allocations from the other services in the overall ecosystem.
The Recommendation Engine microservice supports the same Data Routingcapabilities e.g. Composite Data Sources (https://developer.broadleafcommerce.com/shared-concepts/data-routing#data_sources) which can be overriden as appropriate (even in deployed in the same flex package as others) if necessary
This layer is responsible for consuming data points (which have been harvested by Broadleaf’s Recommendation Engine microservice) and will have model training jobs to run various big data analytics using the Apache Spark engine.
Broadleaf’s Recommendation Engine capabilities are component-ized and this model training layer consists of the following:
Apache Spark Launcher Program
"Bought Also Bought" Spark Training Model Job (.jar)
As mentioned previously, this layer requires a running and functional Apache Spark instance. There are several approaches that are recommended and are outlined in more detail in the Deployment Models section.
For manifest-based Broadleaf projects, you will want to ensure that your manifest.yml has the following configuration setup to introduce all the recommendation engine components into the ecosystem.
First make sure that your project.starterParentVersion is updated to
include the starter parent that supports Recommendation Engine:
|
Important
|
The Recommendations Engine is compatible with the 2.2.x Release Trains |
project:
groupId: com.example.microservices
packageName: com.example.microservices
starterParentVersion: 2.2.[VERSION]
version: 1.0.0-SNAPSHOTNext, make sure that the following Flex packages define the following new "recommendationengine" flexUnit for the following flex package compositions: supporting, min, and one:
flexPackages:
- name: supporting
...
flexUnits: adminnav,adminuser,metadata,notification,recommendationengine,sandbox,search,tenant
- name: min
...
flexUnits: adminnav,adminuser,asset,cart,cartops,catalog,catalogbrowse,content,customer,fulfillment,import,
inventory,menu,metadata,notification,offer,order,orderops,paymenttransaction,pricing,
ratings,recommendationengine,sandbox,scheduledjob,search,shipping,tenant,vendor,creditaccount,bulkops
- name: one
...
flexUnits: adminnav,adminuser,asset,cart,cartops,catalog,catalogbrowse,content,customer,fulfillment,import,
indexer,inventory,menu,metadata,notification,offer,order,orderops,paymenttransaction,
pricing,ratings,recommendationengine,sandbox,scheduledjob,search,shipping,tenant,vendor,creditaccount,bulkopsNext, make sure that the following new "recommendationengine" component is defined as well:
components:
- name: recommendationengine
routed: true
domain:
cloud: recommendationengine
docker: recommendationengine
local: localhost
enabled: false
ports:
- port: 8484
targetPort: 8484
- debug: true
port: 8084
targetPort: 8084The Broadleaf Recommendation Engine requires certain "supporting" components be present for full capabilities. This includes a running Apache Spark cluster.
Make sure your manifest defines the following supporting components:
supporting:
- name: apachespark
platform: apachespark
descriptor: snippets/docker-apachespark.yml
enabled: true
domain:
cloud: apachespark
docker: apachespark
local: localhost
ports:
port: '8080'
- name: apachesparkworker
platform: apachesparkworker
descriptor: snippets/docker-apachesparkworker.yml
enabled: true
domain:
cloud: apachesparkworker
docker: apachesparkworker
local: localhost
ports:
port: '7077'
- name: recommendationenginespark
platform: recommendationenginespark
enabled: true
domain:
cloud: recommendationenginespark
docker: recommendationenginespark
local: localhost
ports:
port: '8485'
sparkui: '4040'
driver: '44720'
blockManager: '44721'
editSource: falseIf you would like to enable sample training data in order to test a training model flow as described in this section:
Example Training Flow, you will need to add the following extensions to your manifest:
extensions:
- artifactId: broadleaf-microservices-starter-heatclinic-recommendationdemo
groupId: com.broadleafcommerce.microservices
version: x.y.zor
extensions:
- artifactId: broadleaf-microservices-starter-telco-recommendationdemo
groupId: com.broadleafcommerce.microservices
version: x.y.z|
Note
|
Note that not all demo extensions are generally available , so either add the heatclinic-recommendationdemo or the telco-recommendationdemo depending on which demo extension module you are utilizing.
|
Finally, if you are planning to run the different "supporting" components locally via docker and docker-compose, ensure you have the following recommendation engine docker components defined:
docker:
components: admingateway,adminweb,database,broker,search,zk,commercegateway,commerceweb,openapi,config,akhq,apachespark,apachesparkworker,recommendationenginesparkOnce you’ve verified configuration in your manifest, you can just run ./mvnw clean install flex:generate to update your project structure accordingly.
Since the Recommendation Engine is an optional piece of the Broadleaf ecosystem, you will need to explicitly define additional properties across a few different Broadleaf microservices in order to fully enable the functionality.
To enable automatic syncing of catalog items to the recommendation engine, you will need to explicitly enable the following properties in your Flex Package that contains the catalog microservice (e.g. browse in the Balanced composition)
Take note of the pros/cons of this approach identified with additional details here
broadleaf:
propagation:
allowCatalogEntityCreationNotification: true
allowCatalogEntityUpdateNotification: true
allowCatalogEntityDeleteNotification: trueTo enable automatic syncing of customers to the recommendation engine, you will need to explicitly enable the following properties in your Flex Package that contains the customer microservice (e.g. cart in the Balanced composition)
broadleaf:
customer:
messaging:
customer-modified:
active: trueIn order to invoke the Apache Spark training job via the Broadleaf Admin using a pre-defined Scheduled Job, you must enable the following property in your data module. (e.g. when utilizing Broadleaf’s Spring Config Server, add these properties to config/insecure/data.yml)
If you are working with the Heat Clinic demo data - set the following property:
spring:
liquibase:
parameters:
blcRecommendationEngineJobEnabled: "true"HINT: after enabling this property and running the
datamodule, you can verify correct initialization if you see a record in thescheduledjob.blc_scheduled_jobtable with ID:RECOMMENDATION_TRAINING
If you are working with the Telco demo data - set the following property:
spring:
liquibase:
parameters:
blcTelcoRecommendationEngineJobEnabled: "true"HINT: after enabling this property and running the
datamodule, you can verify correct initialization if you see a record in thescheduledjob.blc_scheduled_jobtable with ID:telco-RECOMMENDATION_TRAINING
|
Important
|
you must set this property prior to building the data module to ensure that this property is set upon initial run of the seed data in the data store. You can verify that the scheduled job scripts have been loaded into the scheduledjob schema by confirming that you see it in the Admin or (directly in the database) as explained here
|
In order to enable management of dynamic recommendations in the Admin using Content Items and Content Models, you must enable the following metadata properties. Set the following property in the Flex Package that contains your metadata service. (e.g. supporting in a Balanced Flex Composition). More details around this configuration is described here.
broadleaf:
content:
metadata:
enableRecommendationEngineContent: trueTo enable the Recommendation Engine Solr Query Contributor component, you will need to enable the following property in your Flex Package containing the search Microservice.
More details around this configuration is described here.
broadleaf:
search:
recommendation-engine:
enabled: trueSpark Cluster Overview: https://archive.apache.org/dist/spark/docs/3.5.3/cluster-overview.html
Launching Spark Applications: https://archive.apache.org/dist/spark/docs/3.5.3/spark-standalone.html#launching-spark-applications
Using Spark Submit: https://spark.apache.org/docs/latest/submitting-applications.html
Apache Spark Submit Class on GitHub: https://github.com/apache/spark/blob/master/launcher/src/main/java/org/apache/spark/launcher/SparkSubmitCommandBuilder.java
Configuring Environment Variables: https://spark.apache.org/docs/latest/configuration.html#environment-variables
Configuring Logging: https://archive.apache.org/dist/spark/docs/3.5.3/configuration.html#configuring-logging
Runtime Environment Properties: https://archive.apache.org/dist/spark/docs/3.5.3/configuration.html#runtime-environment
Bitnami Apache Spark README: https://github.com/bitnami/containers/tree/main/bitnami/spark#readme