extensions:
- artifactId: broadleaf-microservices-starter-heatclinic-recommendationdemo
groupId: com.broadleafcommerce.microservices
version: x.y.z- v1.0.0-latest-prod
If you would like to experiment with running a model training job on Apache Spark, you will need to have data set up in order for the models to effectively produce recommendations. This guide will go over how you can add some sample training data to your data store, how to invoke a Broadleaf Scheduled Job to start the model training, and finally how you might be able to utilize and surface dynamic recommendations to customers.
One rule of thumb that’s quoted as an ideal minimum anecdotally is that you need less than 99% sparcity of interactions relative to the user and item matrix in order to make good recommendations. So, in order to get a good data set to work with, we’ve created a demo extension library that you can include in your manifest depending on which demo extension you are utilizing.
If you want to pre-poulate your data store with sample data for training, you will need to add the following extensions to your manifest:
extensions:
- artifactId: broadleaf-microservices-starter-heatclinic-recommendationdemo
groupId: com.broadleafcommerce.microservices
version: x.y.zor
extensions:
- artifactId: broadleaf-microservices-starter-telco-recommendationdemo
groupId: com.broadleafcommerce.microservices
version: x.y.z|
Note
|
Note that not all demo extensions are generally available , so either add the heatclinic-recommendationdemo or the telco-recommendationdemo depending on which demo extension module you are utilizing.
|
|
Note
|
the rest of the guide will showcase what running this example training flow looks like on a Telco demo |
Each of these recommendation demo extension libraries will add:
100 customers
1,000 purchases (interactions)
10,000 purchase items spread across the 1,000 purchases
Assuming your manifest.yml file has been modified to include the appropriate extension library (as well as the other needed recommendationengine components), you can run from the manifest directory:
./mvnw clean install flex:generate
./mvnw docker-compose:up
./mvnw spring-boot:run -f ../data
|
Warning
|
Due to the large amount of liquibase changesets contained in these libraries, an initial installation on an empty recommendationengine data store using ./mvnw spring-boot:run -f ../data will likely take some time to complete
|
|
Tip
|
Once the data module has run, you can verify that in your database in the recommendationengine schema, the following tables have been populated: blc_catalog, blc_catalog_item, blc_customer_reference, blc_purchase, blc_purchase_item
|
Notice that in your example demo storefront (Telco Demo being used here as an example) there is a section on the bottom of the homepage showcasing Featured Products. By default, this list is static (managed by Broadleaf’s headless Content Engine) and showcases the same set of products to all customers.
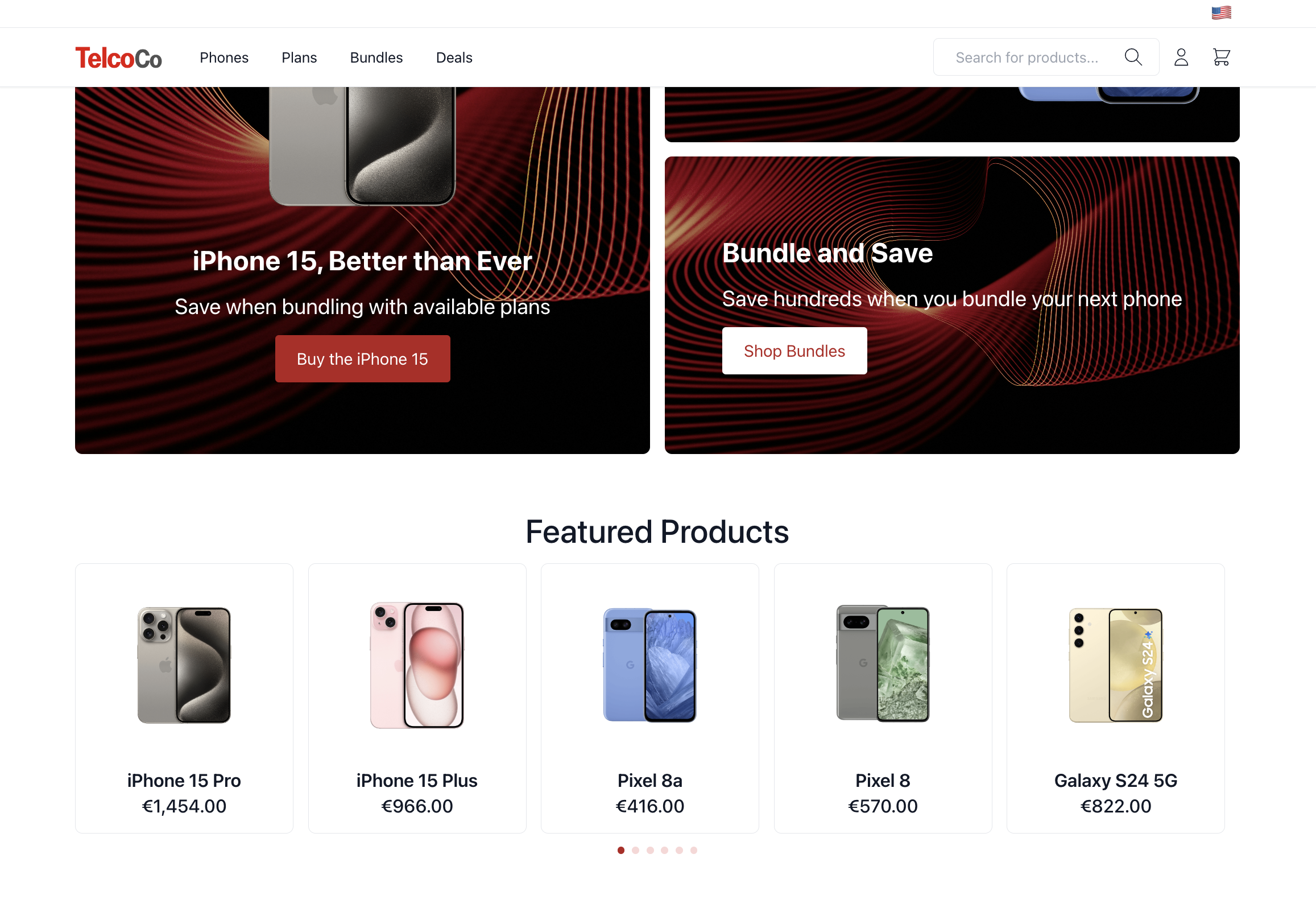
In this example, we’ll change this to showcase dynamic recommendations based on logged in customer.
Broadleaf’s starter data also inserts a "Recommendation Engine Training Scheduled Job" entry which by default is set to run nightly. With that said, you can also kick off the job manually via the Admin console. To do that, log into the admin using the master credentials, and navigate to Processes > Scheduled Jobs. In the list, you should see one called "Run Recommendation Training Job". Click on this, and on the right-hand context menu (3 dots), you will see an option to: Run Now
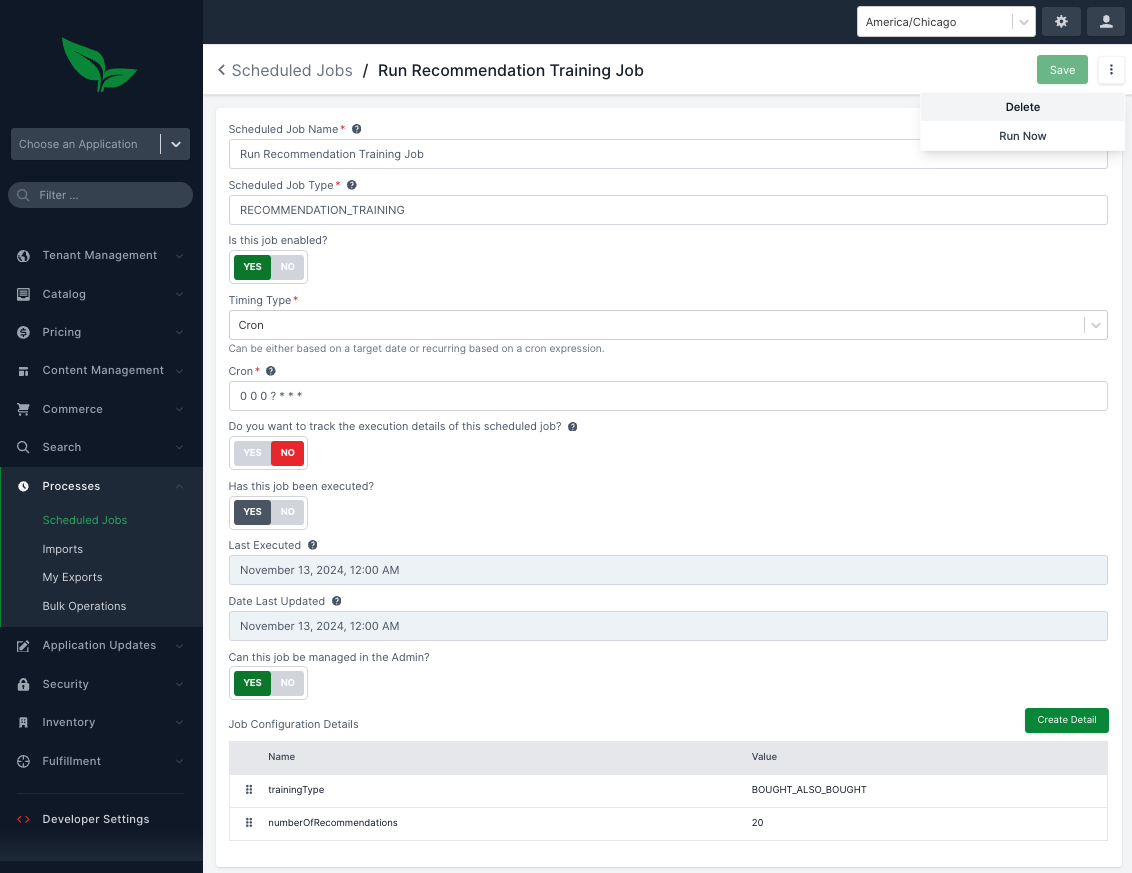
Invoking this job will begin the training model process.
If you are running this example locally with the default single-worker Apache Spark cluster running in Docker, you can view the Apache Spark Master console at: http://localhost:8080/
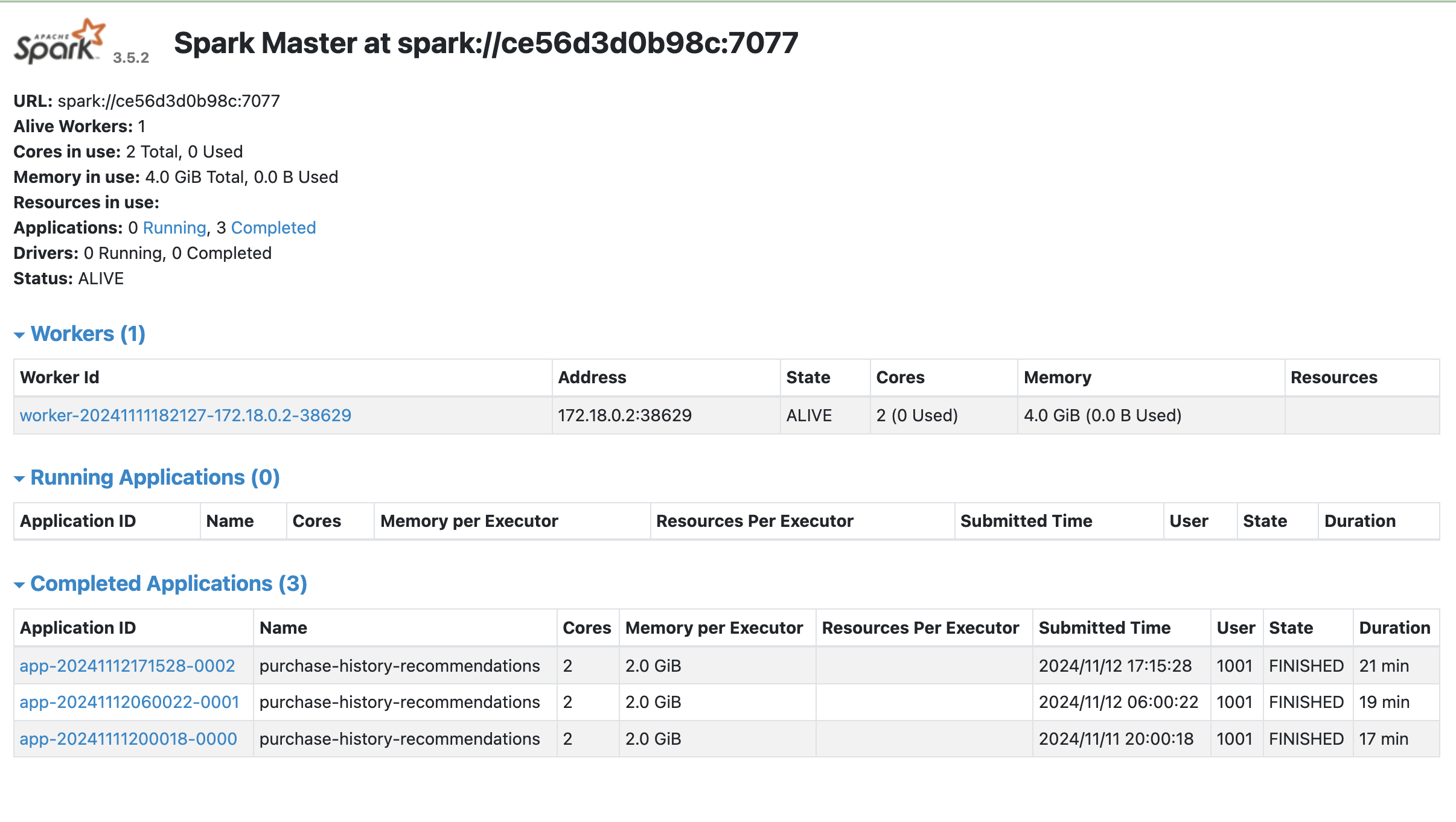
This console shows workers available to the Spark cluster, any running applications (training jobs), as well as any completed jobs.
Once you’ve kicked off the Scheduled Job in the admin, you should be able to see a training model job entry under the "Running Applications" section.
|
Important
|
the default local docker Apache Spark cluster is configured with a 2 core and 2 GB RAM worker instance so as not to overload or consume too many Docker resources. With this configuration, the typical time to complete generating recommendations for the example seed data is ~20 minutes. |
|
Tip
|
In docker, you can tail the logs of the following containers to view progress and see work being done during this training phase: recommendationenginespark, apachespark, and apachesparkworker.
|
After the training model job has completed, you can verify that user recommendations have been generated and persisted to the data store.
In the recommendationengine schema of your data store, you should see data in the blc_user_recommendation and blc_user_recommendation_item tables.
Next, we’ll want to utilize these generated recommendations to the customers on the storefront.
Broadleaf has enhanced the Content Microservice to support building Content Models which have fields that reference a Product the ability to enable "Dynamic Recommendations" based on generated recommendations from the Recommendations Engine.
|
Important
|
to enable management of dynamic recommendations in the Content microservice, you must enable the recommendation metadata property |
broadleaf:
content:
metadata:
enableRecommendationEngineContent: true|
Note
|
you can add the above to the config/insecure properties file for the appropriate flex package that contains the metadata microservice (e.g. one.yml or supporting.yml if using a Balanced Composition) for your Config Service. Once added, you will need to cycle your flex package to pick up and enable the query contributor component.
|
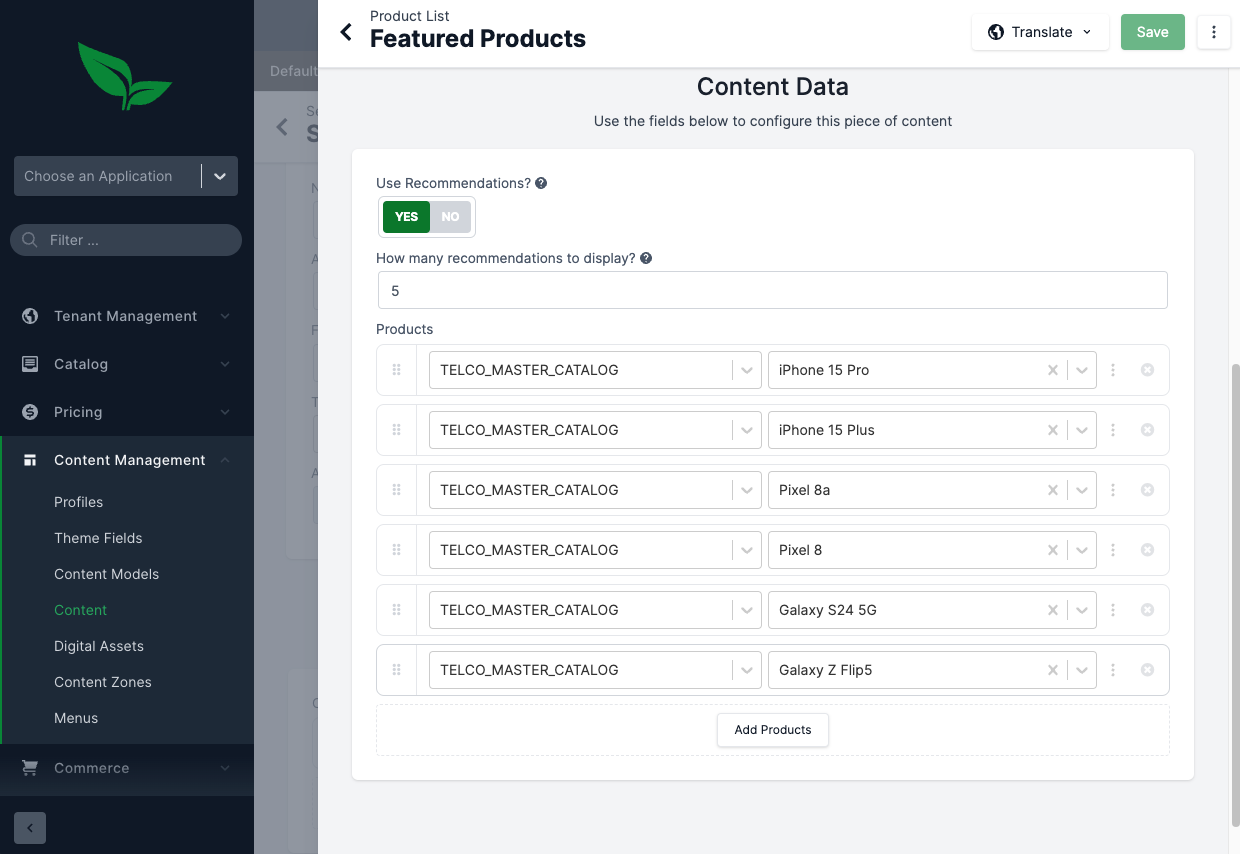
As an example, in the Telco demo admin, if you go to Content Management > Content Models, there is a demo model called Product List. This content model is used on the Home Page to display the featured products.
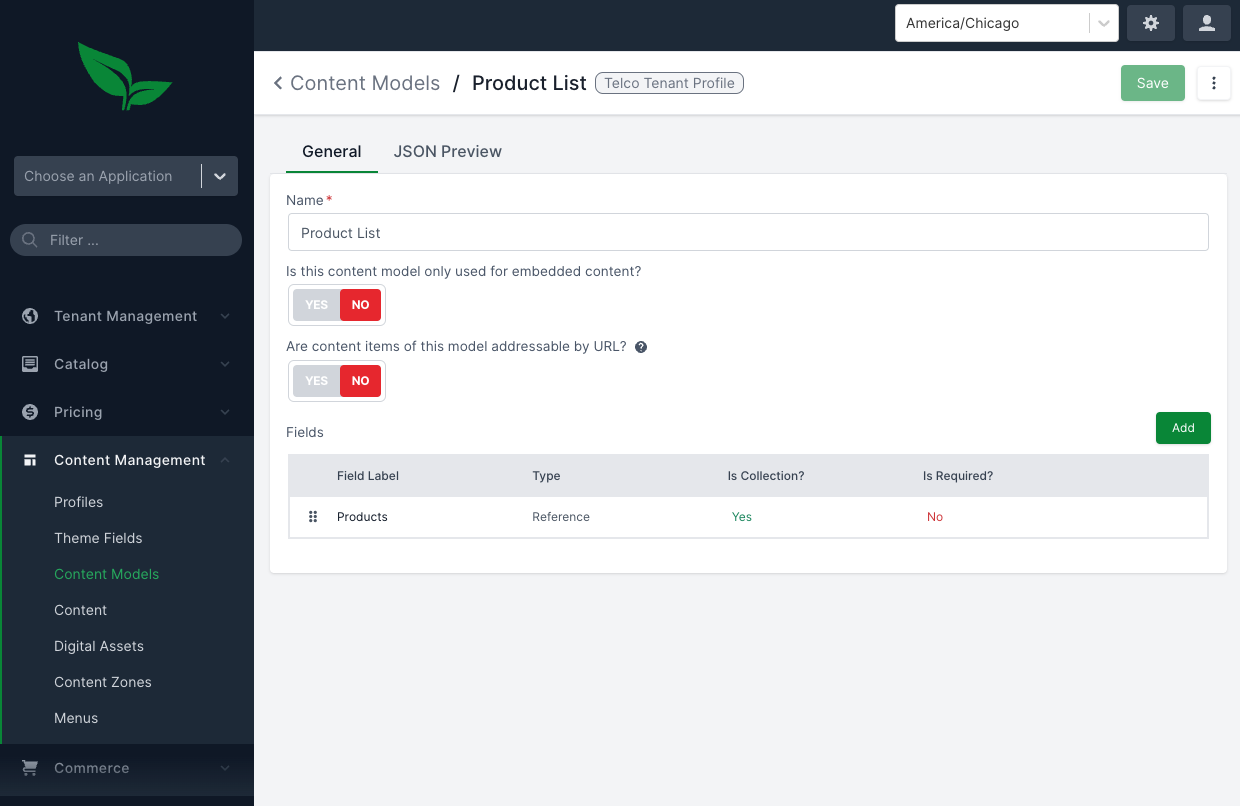
Clicking edit on the products field, brings up a modal where you can enable or disable dynamic recommendations.
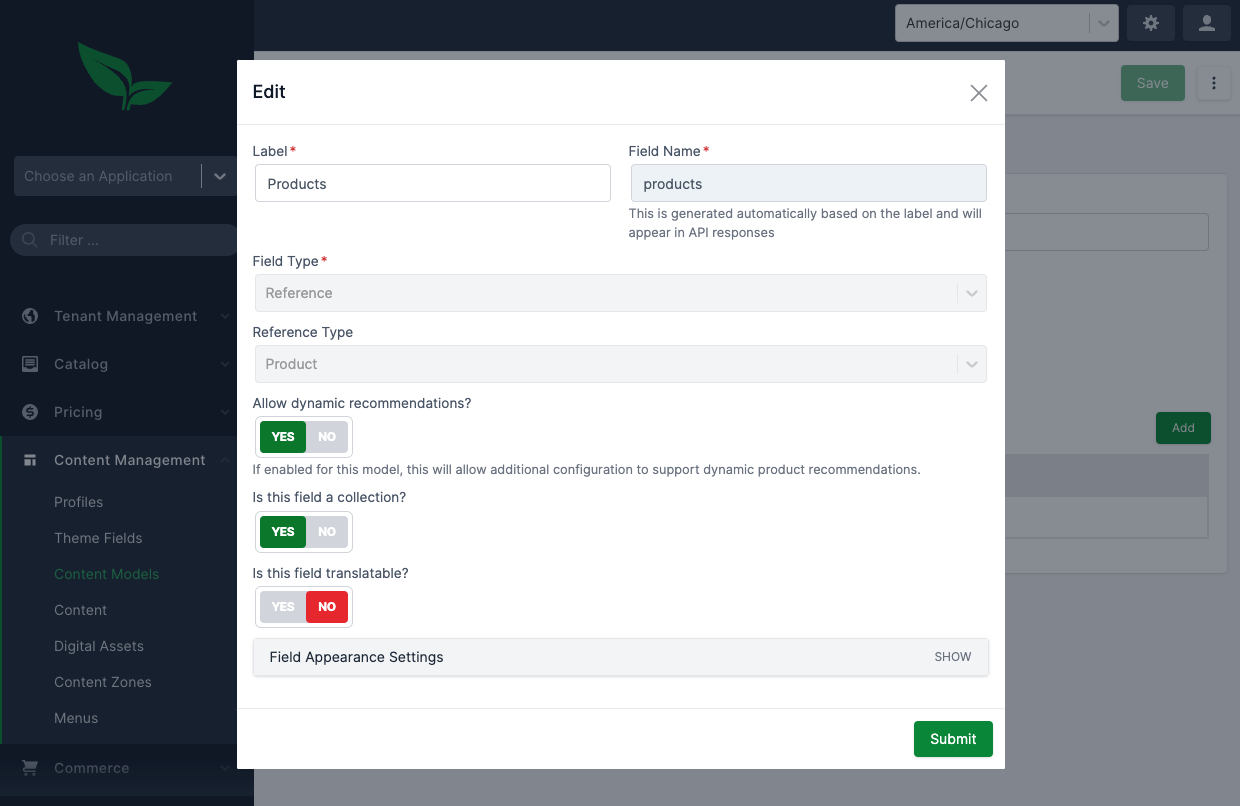
Go ahead and enable dynamic recommendations for this field and save, approve, and deploy the updated Content Model.
Next, we’ll need to update the Content Item that uses this model. In the admin, go to Content Management > Content, and select Content > Homepage Folder. Select the Section 2 content item.
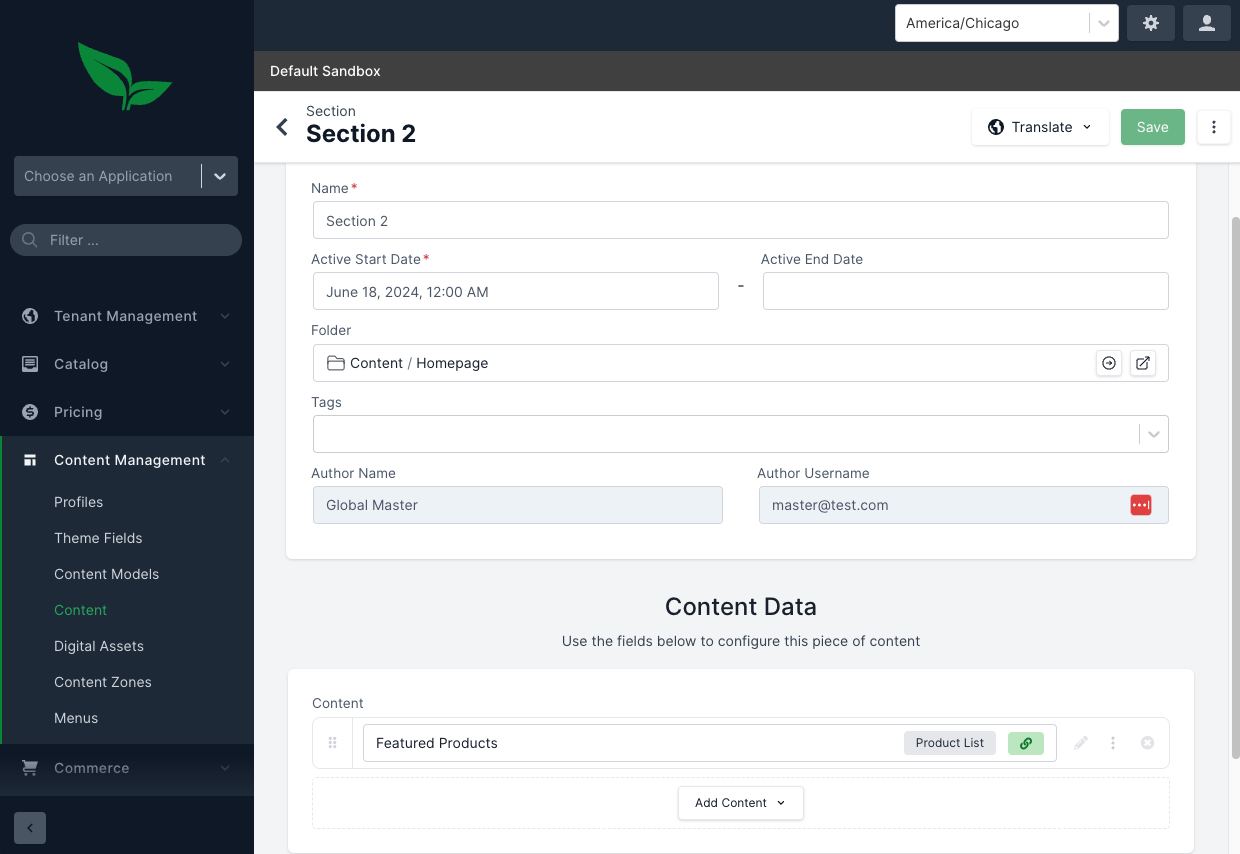
Click on the Featured Products Field to configure the recommendations. Set Use Recommendations to true and specify the number of recommendations you would like to display (e.g. 5)
Go ahead and save, promote, and deploy these changes into production.
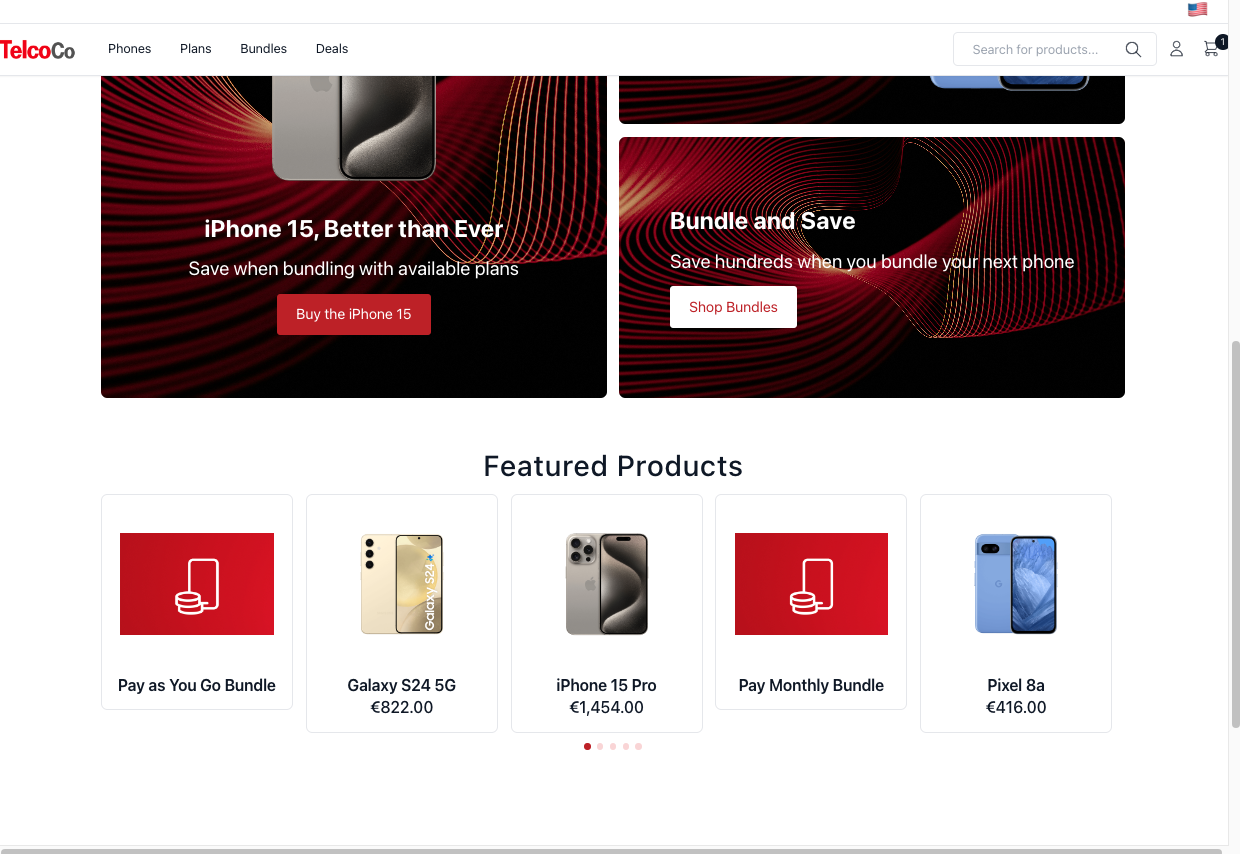
On the storefront as the logged in registered user, if you refresh the homepage (you may need to wait a moment for any caches to expire), you should be able to see the featured products now return you a different set of recommended products.
|
Note
|
you will likely see different products/recommendations based on the products that you purchased previously |
Another mechanism to showcase dynamic recommendations to your users is to automatically "boost" recommended products to the top of the list on a product listing page.
Broadleaf has enhanced the Search microservice to optionally enable a SolrQueryContributor that will enhance the default search queries being performed and to boost certain product identifiers if returned from Broadleaf’s Recommendation Engine.
To enable the Recommendation Engine Solr Query Contributor component, you will need to enable the following property in your Flex Package containing the Search Microservice:
broadleaf:
search:
recommendation-engine:
enabled: true|
Note
|
you can add the above to the config/insecure properties file for the appropriate flex package that contains the search microservice (e.g. one.yml or supporting.yml if using a Balanced Composition) for your Config Service. Once added, you will need to cycle your flex package to pick up and enable the query contributor component.
|
As an example, this is the default product listing page order returned from SOLR for an anonymous user:
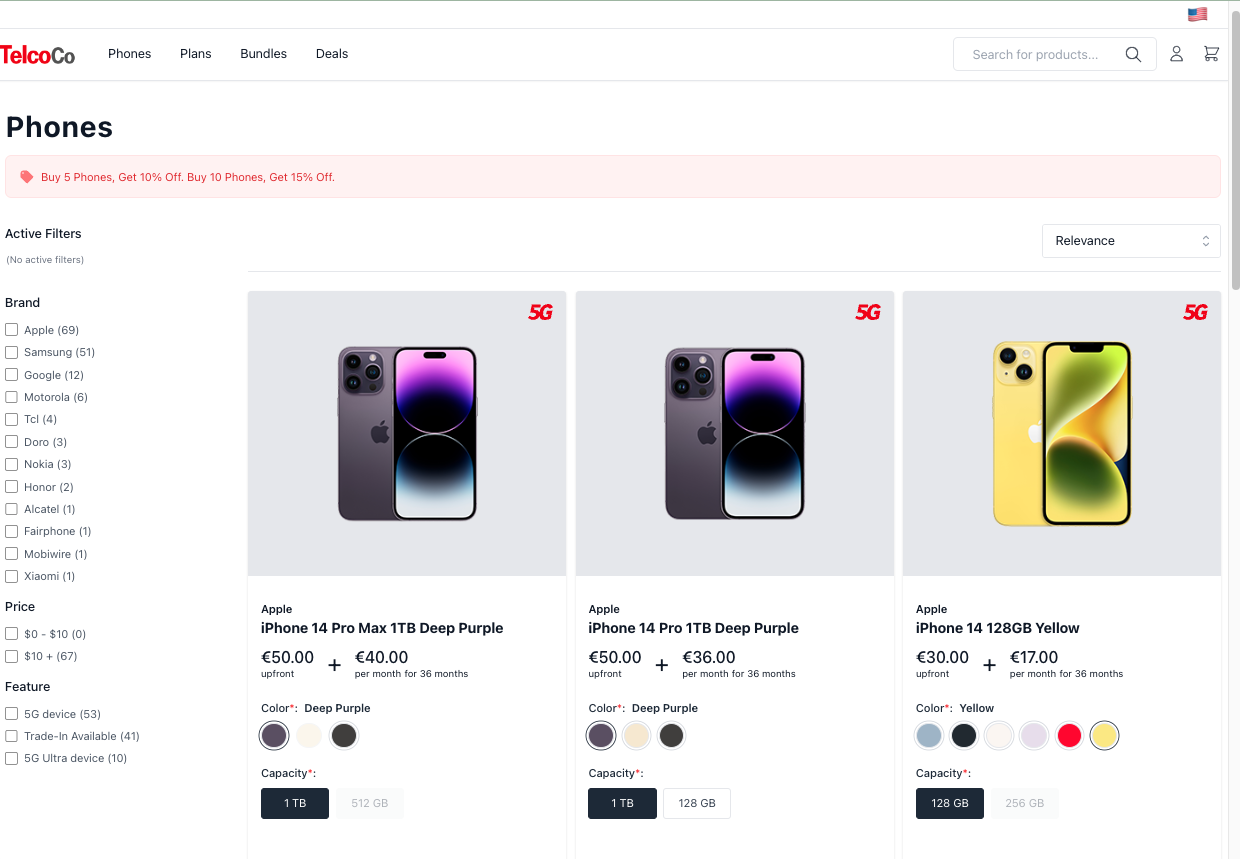
When logged in as a registered user with recommendations generated, the order of the products coming back look like this: