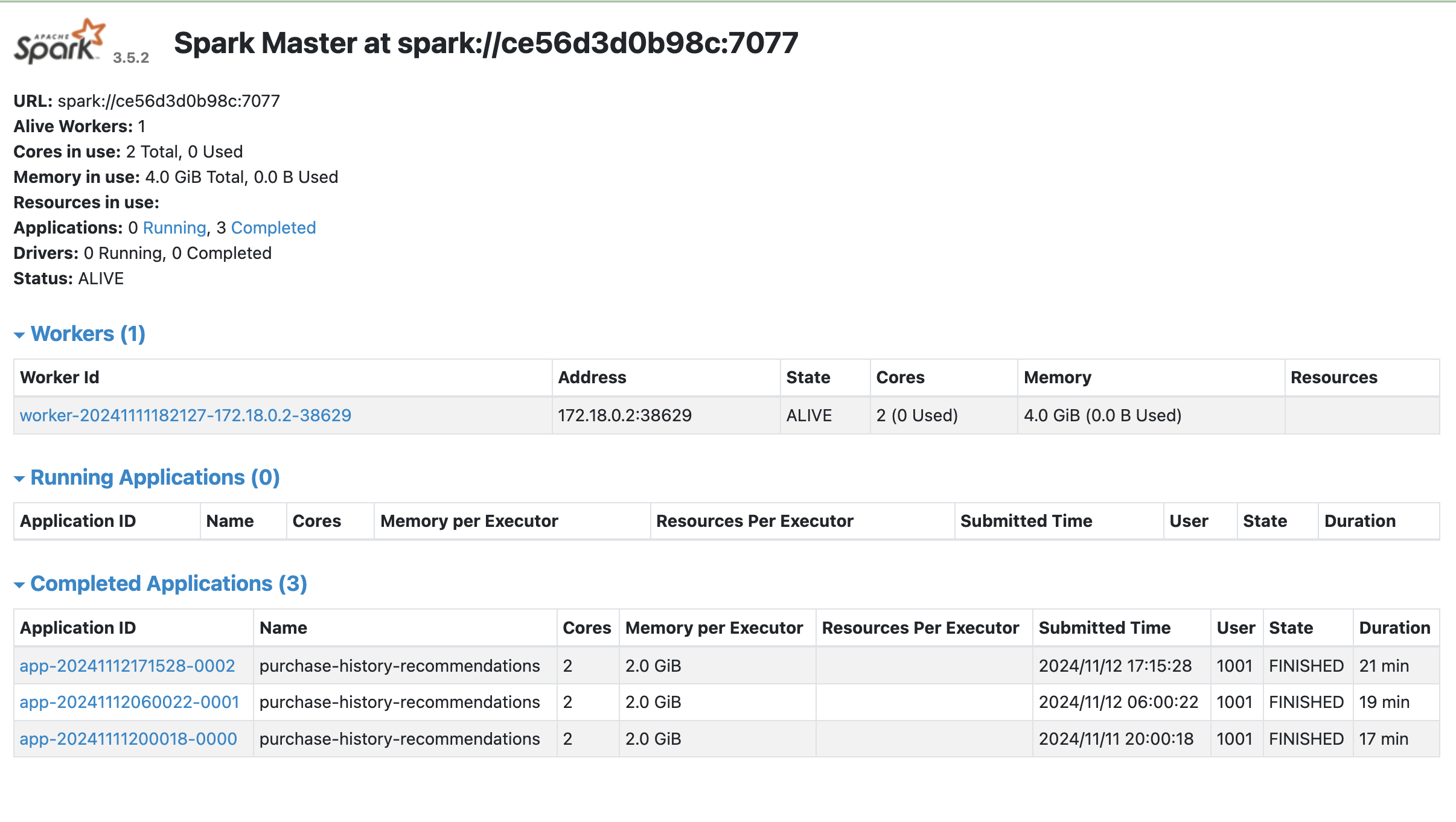
Broadleaf provides a standalone Apache Spark training component which is designed to work and be submitted to any Apache Spark Cluster.
The Bought Also Bought model recommends items that are likely to be bought together. The default algorithm looks at different conversion associations such as purchases. If the same customer buys items in the same purchase within a particular time interval (e.g. a day), they are considered as being "bought together". Additionally, this model also looks at historical purchases, attributes about the customer (segment, account), and other contextual information about those customer/purchase associations to recommend items that are likely to go together.
This component is provided as a .jar file and can be extended or customized to further enhance the training model for your needs.
<dependency>
<groupId>com.broadleafcommerce.microservices</groupId>
<artifactId>broadleaf-recommendation-engine-bought-also-bought-spark-job</artifactId>
<version>${blc.recommendationengine.boughtalsojob.version}</version>
</dependency>