- v1.0.0-latest-prod
Broadleaf provides an optional Apache Spark Launcher program that allows easier connectivity and integration with a running Apache Spark cluster. This spark launcher program has the following properties and responsibilities:
It is a simple Spring Boot application
It has a builtin dependency on Broadleaf’s default training model "JARs" which can be "submitted" to an Apache Spark cluster
has connectivity to Broadleaf’s Config Service to pull in necessary application properties and configuration needed by the training model jobs
exposes an endpoint to start the training model job on an Apache Spark Cluster
expected to be containerized and deployed alongside an Apache Spark Cluster (e.g. as a sidecar in a K8 cluster)
provides an example Dockerfile that contains the necessary Apache Spark binaries and libraries needed to "submit applications" to a running Spark cluster.
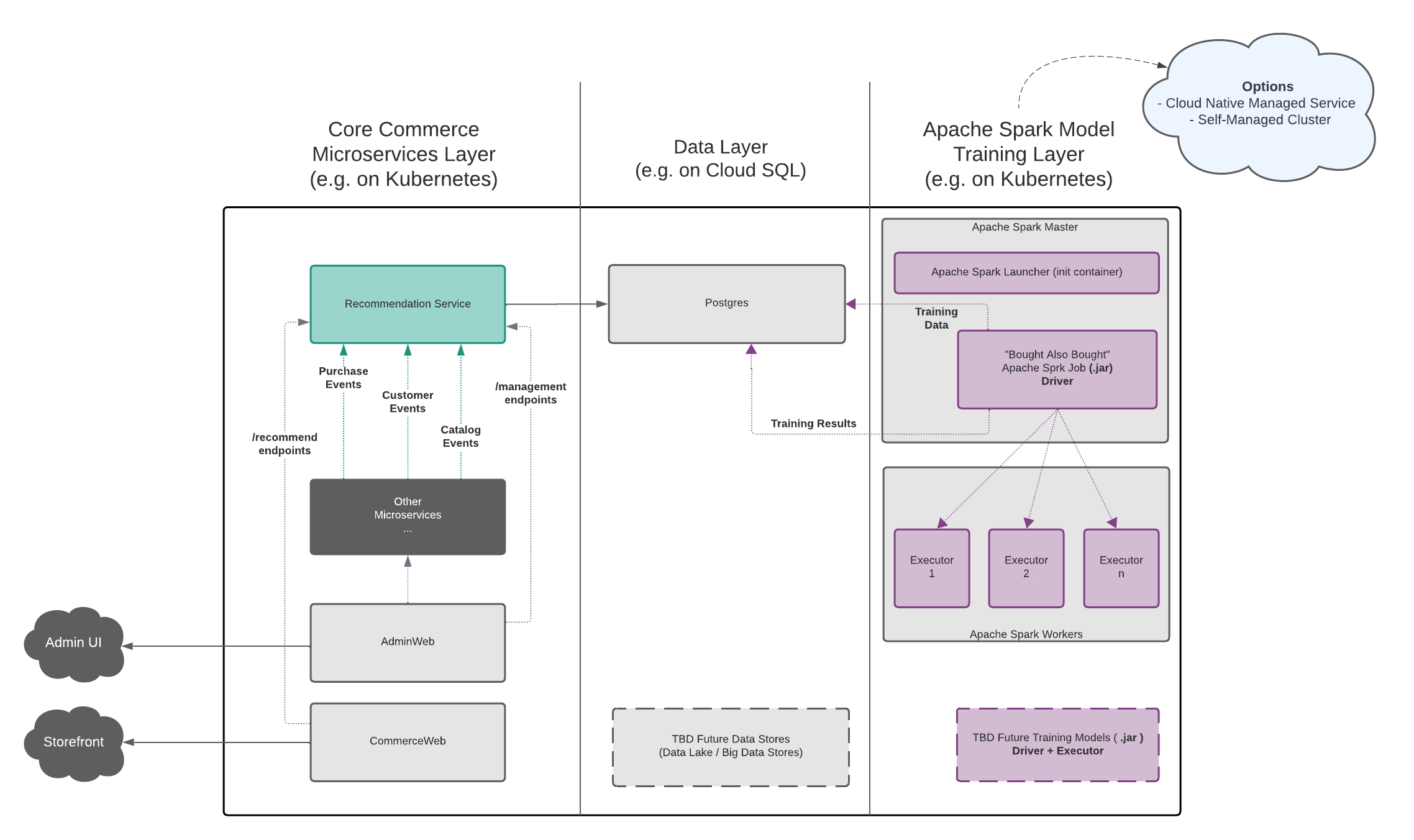
Conceptually, Broadleaf’s Recommendation Engine capabilities can be thought of in 3 distinct "layers":
The core Broadleaf Microservices Layer
The Data Layer
The Model Training Layer (powered by Apache Spark)
The following diagram depicts this in more detail:
Take notice of where the optional Spark Launcher component has the ability to reside in the Model Training Layer.
The Spark Launcher program exposes an endpoint (/recommendation-engine/train-model) to "kick-off" a training model job.
An example cURL might look like:
curl -k -v --location 'https://localhost:8485/recommendation-engine/train-model' \
--request POST \
--header 'X-Context-Request: {"tenantId":"Telco"}' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer eyJh....' \
--data '{
"type":"BOUGHT_ALSO_BOUGHT"
}'Typically, in Broadleaf we would recommend invoking this endpoint via Broadleaf’s Scheduled Job service. Broadleaf’s starter data inserts a "Recommendation Engine Training Scheduled Job" entry which by default is set to run nightly. With that said, you can also kick off the job manually via the Admin console. To do that, log into the admin using the master credentials, and navigate to Processes > Scheduled Jobs. In the list, you should see one called "Run Recommendation Training Job". Click on this, and on the right-hand context menu (3 dots), you will see an option to: Run Now
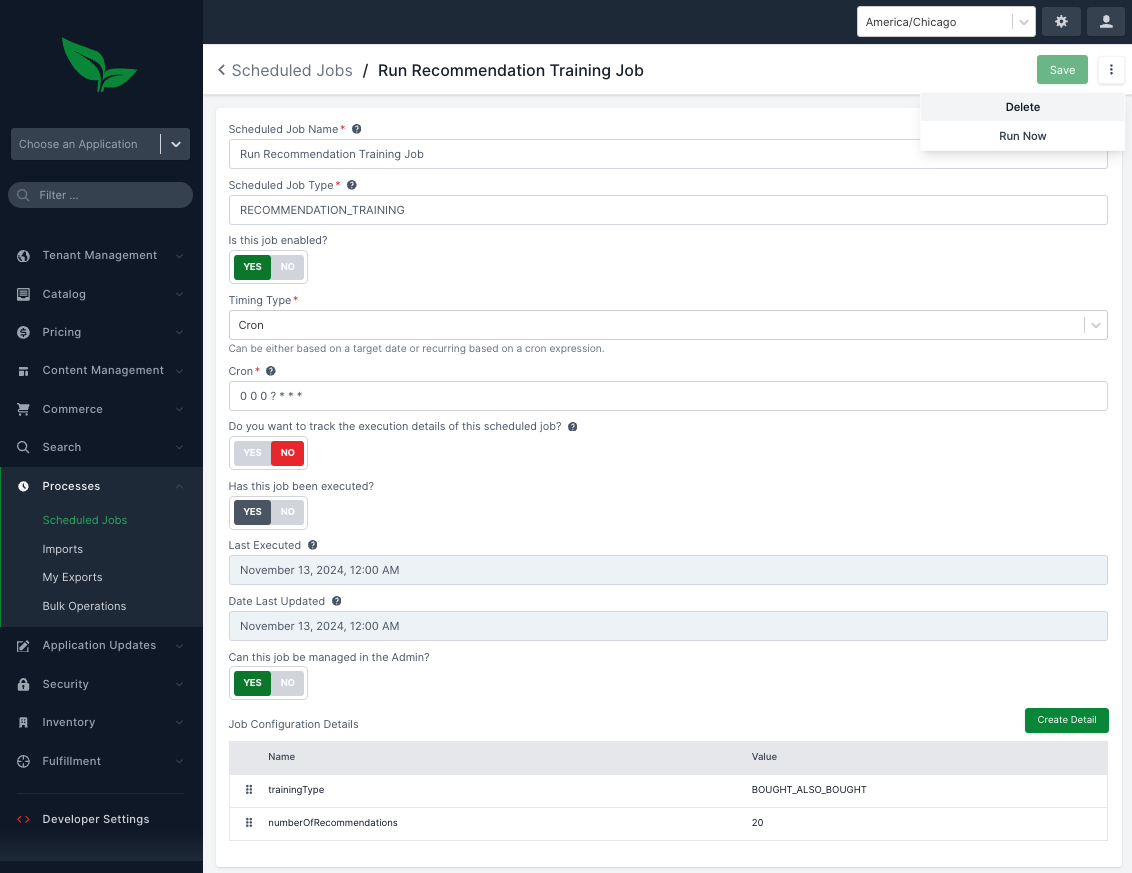
Invoking this job will begin the training model process by invoking the endpoint above.
The endpoint will run through any registered handlers and will begin the training model process by invoking a org.apache.spark.launcher.SparkLauncher instance.
Under the hood, a Spark Launcher invokes an Apache Spark Submit flow.
The parameters and variables (such as DB connectivity) that are necessary for the training job and are passed to the Spark Submit call can be reviewed in more detail in this class: com.broadleafcommerce.recommendationengine.sparklauncher.service.SparkLauncherService
More details around launching Spark applications can be found on the Apache Spark documentation:
the default DB credentials that are passed to Spark Submit are injected into the application on startup using Broadleaf’s Spring Cloud Config Service (along with with other configuration parameters).
As a convenience, this launcher program also defines a few dependencies that are passed into "Spark Submit" for the training model job. This includes things like:
A Postgres Driver JAR (postgresql-42.7.3.jar)
A Broadleaf Common Lib Jar (broadleaf-recommendation-engine-core-lib-x.y.z.jar)
A ULID Jar (ulidj-1.0.4.jar)
The "Bought Also Bought" training model JAR (broadleaf-recommendation-engine-bought-also-bought-spark-job-x.y.z.jar)
|
Important
|
If you are running a DB other than postgres, you will need to customize the launcher following directions in the next section to include the appropriate driver for you proper connectivity to your specific DB. This driver will be passed to Apache Spark and given to all the nodes in the cluster running the training model. |
Broadleaf provides the source for this launcher component so that implementations have the freedom to augment and change the default functionality for their needs.
To do this, you can set editSource to true in your recommendationenginespark component of your manifest.yml:
supporting:
- name: recommendationenginespark
platform: recommendationenginespark
enabled: true
domain:
cloud: recommendationenginespark
docker: recommendationenginespark
local: localhost
ports:
port: '8485'
sparkui: '4040'
driver: '44720'
blockManager: '44721'
editSource: false <---------- change this to true