- v1.0.0-latest-prod
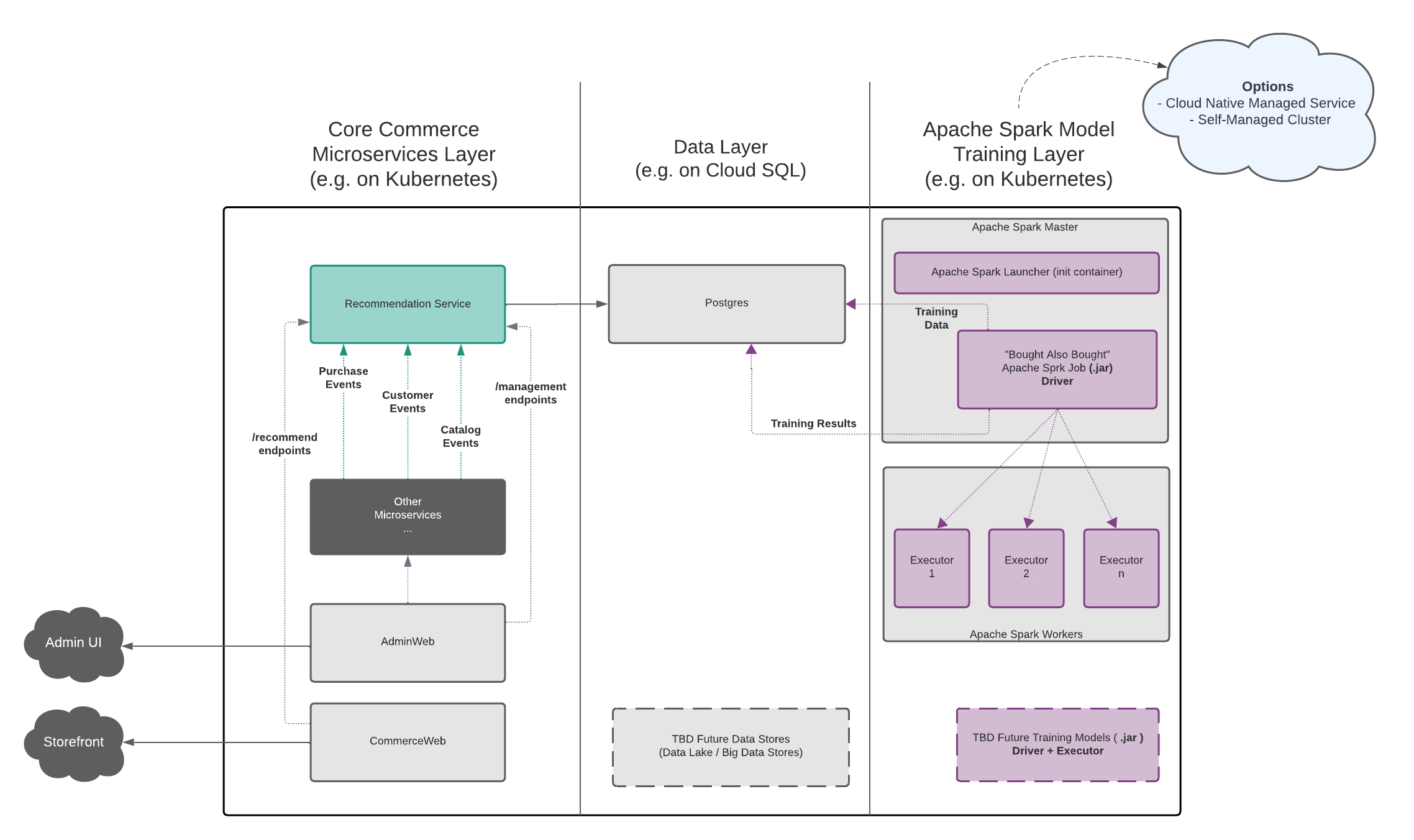
Conceptually, Broadleaf’s Recommendation Engine capabilities can be thought of in 3 distinct "layers":
The core Broadleaf Microservices Layer
The Data Layer
The Model Training Layer (powered by Apache Spark)
The following diagram depicts this in more detail:
this layer consists of the existing Broadleaf Microservices ecosystem such as the Flex Packages (e.g. browse, cart, supporting, etc…) and other supporting applications typically running on Kubernetes
Broadleaf provides an individual "Recommendation Engine" service that is deployed in this layer (typically inside a Flex Package).
This recommendation component contains several listeners and endpoints to facilitate capturing and storing certain events and data points that will be stored in the configured data store.
By default, this Recommendation Engine microservice component will store certain data points into a relational data store following the same patterns as other Flex Packages in the Broadleaf ecosystem. As with the other microservices, the Recommendation engine assumes an isolated bounded context and will persist data into a recommendationengine schema
This data store will also be used by the "Model Training Layer" to store various training results data points which can be queried and utilized by the Recommendation Engine service when needed
Depending on the amount of data points you collect for training, you may want to consider configuring the Recommendation Engine microservice to utilize its own Database (separate from the other Broadleaf microservices, i.e. not just a separate schema) in order to separate and scale this service in isolation and not impact DB resource allocations from the other services in the overall ecosystem.
The Recommendation Engine microservice supports the same Data Routingcapabilities e.g. Composite Data Sources (https://developer.broadleafcommerce.com/shared-concepts/data-routing#data_sources) which can be overriden as appropriate (even in deployed in the same flex package as others) if necessary
This layer is responsible for consuming data points (which have been harvested by Broadleaf’s Recommendation Engine microservice) and will have model training jobs to run various big data analytics using the Apache Spark engine.
Broadleaf’s Recommendation Engine capabilities are component-ized and this model training layer consists of the following:
Apache Spark Launcher Program
"Bought Also Bought" Spark Training Model Job (.jar)
As mentioned previously, this layer requires a running and functional Apache Spark instance. There are several approaches that are recommended:
Similar to how we recommend implementations consider using a cloud native managed database, many cloud providers all provide native apache spark managed services such as:
Google has a managed service called Dataproc https://cloud.google.com/dataproc which can run Apache Spark Jobs
AWS has a managed service called EMR https://aws.amazon.com/emr
Azure has a managed service called Azure Synapse https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-overview
DataBricks which also provides managed Spark options
Because Broadleaf provides component-ized resources, you can utilize and run any of the provided Apache Spark compatible training model jobs on any running instance of Apache Spark.
Refer to the documentation of the managed Apache Spark provider to understand how to upload and run an Apache Spark job component (e.g. the broadleaf-bought-also-bought-training.jar) with configuring the appropriate ENV properties (such as DB connection info etc…)
If you are looking to deploy and manage Apache Spark yourself, Spark has different deployment models depending on what type of environment you’re running in. Please refer to the Apache Spark documentation for more details: https://spark.apache.org/docs/latest/cluster-overview.html
Broadleaf does not prefer or recommend a particular option and it will be up to your implementation to pick the cluster model that works best for your ecosystem
As a SIMPLE REFERENCE AND EXAMPLE ONLY, Broadleaf (by default) will initialize a simple "standalone" cluster when running the recommendation engine locally. This setup uses the https://spark.apache.org/docs/3.5.2/spark-standalone.html model which is the simplest way to setup a spark cluster and will utilize Spark’s built in cluster-manager capabilities.
If you are running on Kubernetes, you may want to consider configuring your K8 cluster to act as the cluster manager instead: https://spark.apache.org/docs/latest/running-on-kubernetes.html.
Any configurations and setup options such as security and policies surrounding your cluster deployment are outside the scope of what Broadleaf provides. We encourage implementors to refer to the Apache Spark documentation for more details.
As a local reference example only, Broadleaf initializes a default standalone Apache Spark cluster that utilizes Bitnami’s Apache Spark Docker images.
More details on this image can be found here: https://hub.docker.com/r/bitnami/spark
The docker-compose generated by the Broadleaf Initializr will generate docker components influenced by the default docker-compose setup as referenced here: https://github.com/bitnami/containers/blob/main/bitnami/spark/docker-compose.yml
The local setup will start up a single master spark node and a single worker spark node.
If you would like to experiment deploying a simple standalone Apache Spark cluster using Helm, Bitnami provides helm charts for deploying a simple 1 master, 2 worker node persistent standalone cluster here: https://artifacthub.io/packages/helm/bitnami/spark
Assuming you have a default Broadleaf Kuberenetes cluster setup as described here: https://developer.broadleafcommerce.com/tutorials/devops/deploy-to-kubernetes
You can run a default Bitnami installation with the following example blc-values.yaml overrides
helm install spark oci://registry-1.docker.io/bitnamicharts/spark -f blc-values.yamlExample blc-values.yaml Overrides:
global:
imagePullSecrets:
- blc-registry-creds
master:
extraVolumes:
- name: common-keys-projected-volume
projected:
sources:
- secret:
name: common-blc-app-ssl-keystore
items:
- key: base64KeystoreFileContents
path: https-keystore.jks
optional: true
- secret:
name: common-cfgsrvr-ssl-truststore
items:
- key: base64TruststoreFileContents
path: cfg-server-ssl/https-truststore.jks
optional: true
- secret:
name: common-kafka-client-ssl-truststore
items:
- key: base64TruststoreFileContents
path: kafka-truststore.jks
optional: true
- secret:
name: common-zk-kafka-client-jaas-conf
items:
- key: base64LoginConfFileContents
path: zk-kafka-client-jaas.conf
optional: true
sidecars:
- name: blc-recommendationenginespark
image: repository.broadleafcommerce.com:5001/broadleaf/recommendationenginespark-monitored:1.0.0-SNAPSHOT
imagePullPolicy: Always
ports:
- containerPort: 8485
protocol: TCP
envFrom:
- configMapRef:
name: common-environment-env
- secretRef:
name: common-cfgsrvr-secret-envs
optional: true
env:
- name: RUN_BLC_SPARK_LAUNCHER
value: 'true'
- name: BROADLEAF_ENVIRONMENT_REPORT_DISABLED
value: 'false'
resources: {}
volumeMounts:
- name: common-keys-projected-volume
readOnly: true
mountPath: /var/keys
service:
extraPorts:
- name: 'blc-spark-launcher-sidecar'
protocol: TCP
port: 8485
targetPort: 8485All the blc-value overrides above just defines an extra sidecar container to load the Broadleaf Apache Spark Launcher program to the master node. This exposes a single endpoint to begin scheduling the Bought Also Bought (and any additional) training models on the running Spark cluster.
If you plan to set this up for any production-level environment, it is important to refer to any configurations and setup options such as security and policies as defined by the Bitnami Chart configuration and recommendations. Security configurations and policies for this helm chart are outside the scope of what Broadleaf provides. We encourage implementors to refer to the Apache Spark and Bitnami Chart documentation for more details.