- v1.0.0-latest-prod
The Indexing subsystem is a general-purpose process to build or rebuild a search index (e.g. Solr Collection) from another data source. There are two types of (re)indexing in Broadleaf:
Full (Re)indexing (FrI)
Incremental (Re)indexing (IrI)
FrI is the process of building or rebuilding an index entirely. This typically involves truncating the original index, if applicable, reading data from a data source, constructing index-specific documents (or records), writing to the index, and any cleanup activities. The index in question is usually a background or offline index that is not being used by customers, but that could be made foreground or public after FrI occurs, usually by swapping or re-aliasing indexes.
IrI is the process of making small, incremental changes to a foreground, or public, index that is visible by customers. This usually involves receiving an asynchronous event (e.g. via Kafka) and modifying the data in the foreground, or visible, index. No swapping or realiasing of indices is necessary with IrI.
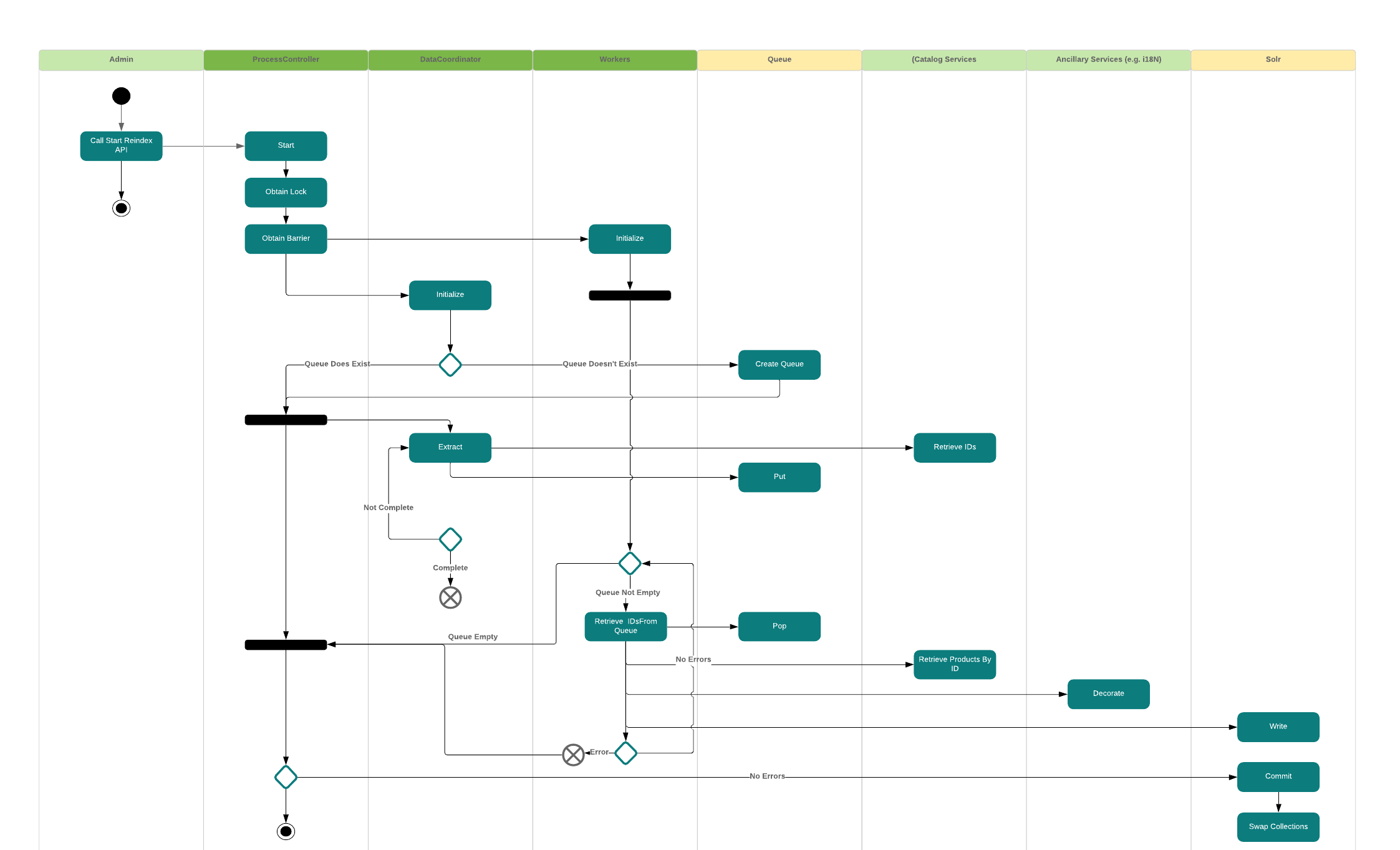
This represents a high level overview of the FrI process:
Generally speaking, when an indexer kicks off, it attempts to create a Lock. If it can create a Lock, distributed or local, it raises an event that a
reindexing process is begininning which notifies certain components to prepare to begin indexing. The control thread then begins reading context IDs as batches from
a source system. This is typically a REST API, but it could be any source of data that can provide context IDs for items that need to be reindexed. The control thread
then begins batching IDs and putting them on a Queue (a java.util.concurrent.BlockingQueue). The blocking queue prevents the control thread from over-running the
worker threads in a way that could cause an OutOfMemoryError. Each worker thread then polls the BlockingQueue to retrieve a batch of context IDs to process. It then
reads the complete set of data from an API or "data source" for the batch of IDs.
This allows a single control thread to fetch the smallest amount of data (an ID) in large batches, break the batch into smaller batches for processing by worker threads, prevent duplicate reads, and ensure that when the end of the data is reached the data is finalized so that there is no ambiguity about how much data is left to process.
There are several important components to consider specifically during the reindex process:
GenericSearchIndexMasterProcessLauncher (abstract) - for example ProductSearchIndexMasterProcessLauncher (concrete)
Obtains a lock from the lock service and kicks off a process to begin reading and reindexing data
GenericSearchIndexWorkerProcessLauncher (abstract) - for example ProductSearchIndexWorkerProcessLauncher (concrete)
Responds to an event to kick off the workers that will do most of the reading and writing of indexed data
QueueLoader (abstract) - for example DefaultProductQueueLoader (concrete)
A component that will begin to load context IDs into a queue for processing by the worker threads
DocumentBuilder (abstract) - for example ProductSolrDocumentBuilder (concrete)
A component to take in Indexable data and produce a Search Engine-specific document (e.g. SolrInputDocument) or record to be written to the search engine
LockService (abstract)
Offers a Lock to ensure that only one control thread can execute certain flows (see DefaultLocalJvmLockService)
QueueProvider (abstract)
A mechanism to provide access to a java.util.concurrent.BlockingQueue (see DefaultLocalQueueProvider)
ProcessStateService (abstract) - for example DefaultProcessStateService (concrete)
A service to allow components (or events) to trigger changes in the state of the reindex process
ProcessStateHolder
A component to keep track of the state of the reindex process including allowing for fast fail when an error occurs as well as number of documents indexed, etc.
While you can override almost any Broadleaf component with a custom component, most implementors will not need to override the plumbing for reindexing processes. Rather, the things that are most typically customized or overridden are:
Field Definitions - DB entries that define which fields and field variants should be indexed or added to a document (or searchable record)
DocumentBuilders - Instances of com.broadleafcommerce.search.index.core.document.DocumentBuilderContributor that allows you to programmatically, or more surgically, contribute to the document or record that is being indexed
Other things that are typical when customizing the behavior or performance characteristics of Indexers are:
Make use of distributed indexers using Apache Ignite, for example. See details here
Note that this is a more complicated deployment and my not be necessary for everyone. This is more appropriate for huge data sets and situations where large data sets need to be reidexed often or in very short periods of time