- v1.0.0-latest-prod
Broadleaf’s Search Services are a set of APIs that allow you to search for specific entities. By default, Broadleaf’s Search Services use Apache Solr as the back-end Search Engine. An Indexer writes documents (or records) to Solr or another Search Engine. Then those doucments can be queried, filtered, and faceted by the Search Services. Broadleaf’s Search Services are an API in front of the Search Engine or Appliance (e.g. Solr) - which provides its own APIs - that provide a standard interface to search and browse for Catalog and Product data, and search Customer and Order data via the Admin.
Because Broadleaf uses Solr as a default Search Engine, Catalog, Customer, and Order data are stored in different Solr Collections (indexes). There are two Collections for each domain area (Catalog, Customer, and Order). So, by default, Broadleaf maintains 6 Solr Collections - 1 foreground and 1 background Collection. The foreground collection is considered the active collection. The background collection allows for data to be truncated and fully reindexed without interrupting ongoing search functionality. So searches are always performed against the foreground collection. When the full reindexing occurs for a Collection, the aliases are exchanged and the background Collection becomes the foreground Collection while the current foreground Collection becomes the background Collection. Thus queries can continue to operate against the foreground Collection without interruption.
Broadleaf Commerce Search Services maintain metadata for things like the following:
FieldDefintion
This component generally defines a field that will be indexed and may be Searchable. This contains metadata about whether this is a multi-valued field, whether it is searchable, how to access it on the source object (object graph), and other data such as whether this field is searchable, sortable, and faceted
An example of this could be name, which might define a Product name
FieldVariant
FieldDefinitions can have multiple variants. Variants are different ways of indexing and searching the same data. Text fields most commonly have variants that describe different ways that fields are tokenized, parsed, filtered, and indexed.
Given a field definition of name, which is a text field on Product, it may be advantageous to search for exact matches, phonetic matches, partial matches, etc.
Variants equate to different fields in Solr, but the same field or data a source object or record. So, with the name example,
in Solr, there may be the variants name_s, name_t, name_tta. In these cases, a document in Solr would contain 3 different fields that index the same
data differently. Each of these fields can have different weight in searches, and they will match differently based on the input being searched or filtered on.
|
Important
|
When using phonetic matching, it is crucial to make sure that the language(s) your applications use are supported by the configured Search Engine (e.g. Solr) and its analyzer, to avoid adverse search behaviors (e.g. irrelevant data being matched). Out of the box, Broadleaf uses Apache Solr and Beider-Morse Phonetic Matching (BMPM) analyzer for phonetic matching. For all the other analyzers and supported languages in Apache Solr, please see Solr’s Phonetic Matching Reference Guide for more details |
FieldDefinition and FieldVariant entities are the most important entities used by Broadleaf’s Search Services to build queries. But there are a number of
additional entities that provide additional metadata to the Search Services to constuct more advanced queries, including TypeAhead, Facet, FacetRange,
SortOption, SearchRedirect, and others.
SearchRedirect is particularly interesting because it allows you to short circuit a query against the search engine and prescribe a redirect in the response.
This is useful when you want to take the user to a specific page for certain keywords such as a marketing term, buzzword, sale name, etc.
Modifying this metadata, typically via the administrative console, is one of the most direct ways to affect the way that entities are indexed, and how entities are queried, filtered, and faceted.
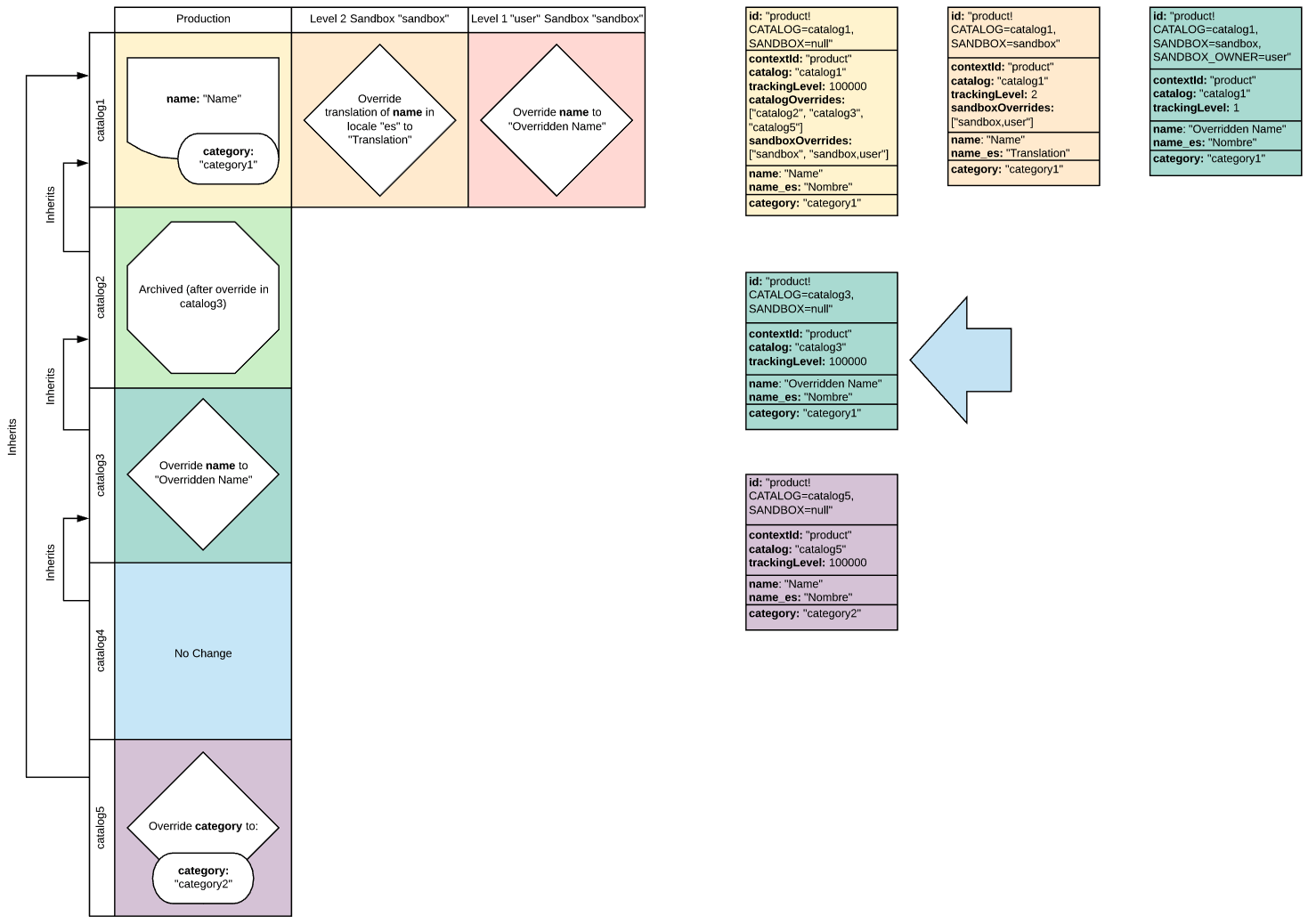
Search Services are required to return the right data in a multi-tenant environment. This data could be any data that is indexed, but in Broadleaf it is typically Catalog, Customer, and Order data. This data is discriminated differently, and catalog data in particular can exist in multiple states across multiple catalogs and sandboxes.
Broadleaf Search Services and the default Solr implementation has mechanisms called SolrQueryContributor. These
components are used to modify the Solr Query, typically by applying additional predicates. The following SolrQueryContributors are examples of things that can modify or contribute
to Solr Queries:
ApplicationTrackableSolrQueryContributor
CatalogTrackableSolrQueryContributor
CustomerContextTrackableSolrQueryContributor
DefaultSolrActiveDateContributor
SandboxTrackableSolrQueryContributor
TenantTrackableSolrQueryContributor
Implementing the SolrQueryContributor (or AbstractSolrQueryContributor) or overriding these components is the easiest way to
affect Solr queries from a code perspective. The other is to configure the Search Service metadata, such as FieldDefinitions,
FieldVariants, etc., which are used to construct the queries.
The following diagram illustrates how Narrowing works to obtain the correct version of a document given the Application, Tenant, Customer, Catalog, or Sandbox: