- v1.0.0-latest-prod
There are a number of shared libraries that, together, assemble Search and/or Indexer services. The default implementation(s) use Apache Solr, but these libraries and APIs were designed to be pluggable to allow for integration with other Search Engines.
Almost all components in all libraries are Spring Beans and can be extended, overridden, or augmented via configuration.
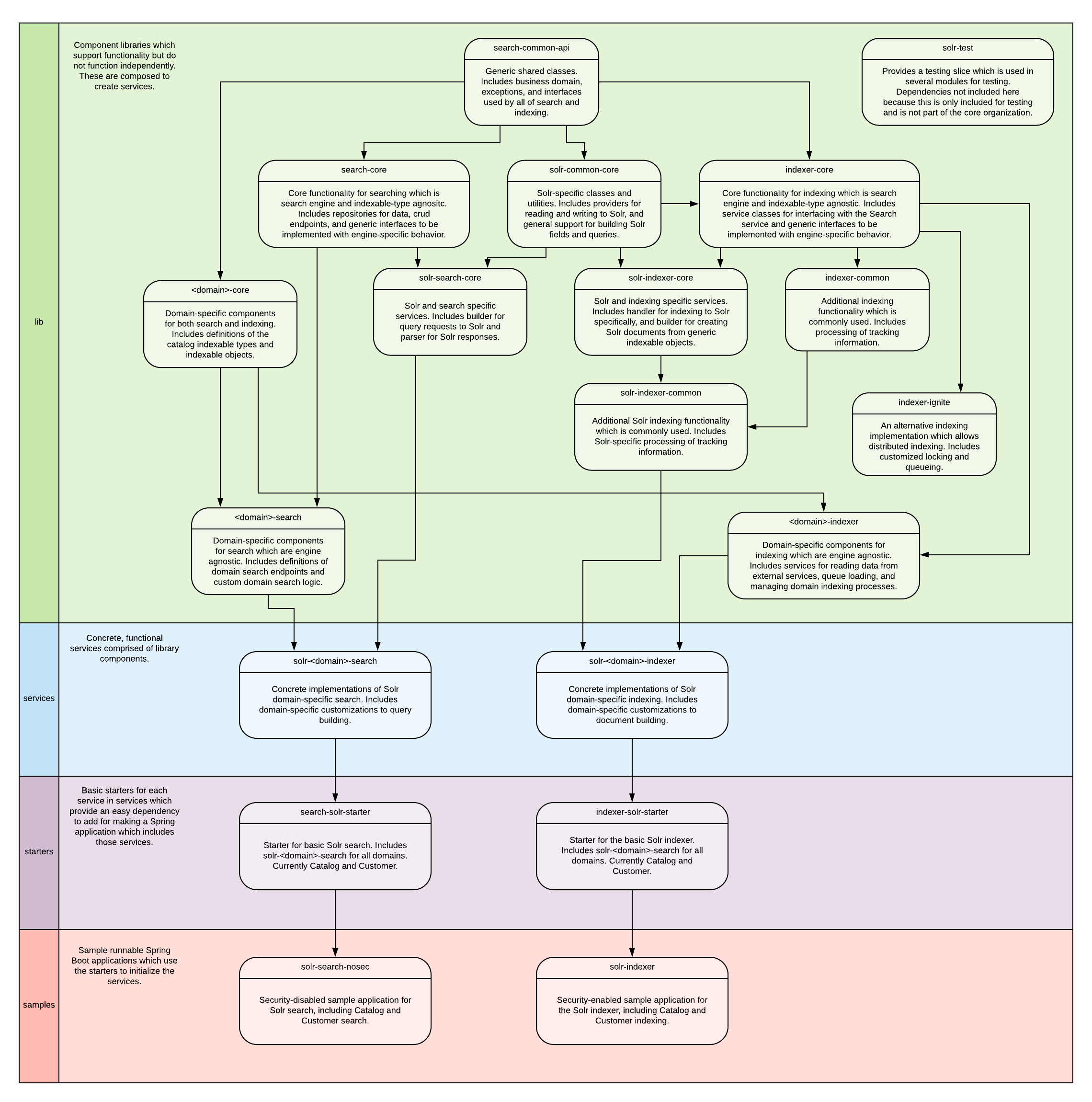
This diagram provides a summary of how the libraries described, below, are organized:
This library provides Search Engine-agnostic components to define Catalog items, especially Products, according to what needs to be indexed and searched.
This library provides Search Engine-agnostic components for indexing Catalog data such as products. These components understand how to fetch and queue product data for processing by background threads.
This library provides Search Engine-agnostic components for executing searches or queries for Catalog data against a general purpose
search API. Included is the CatalogSearchEndpoint REST controller.
This library provides Search Engine-agnostic components to define Customers according to what needs to be indexed and searched.
This library provides Search Engine-agnostic components for indexing Customer data, typically for use by the Administrative Console. These components understand how to fetch and queue Customer data for processing by background threads.
This library provides Search Engine-agnostic components for executing searches or queries for Customer data against a general purpose
search API. Included is the CustomerSearchEndpoint REST controller.
This library contains a set of Search Engine-agnostic components that provide the core Indexer functionality. This library is responsible for concurrency, queueing, locking, state management and certain event handling. Generally speaking, this library provides most of the control logic to support (re)indexing activities.
The Apache Ignite library is optional, but provides Search Engine-agnostic facilities to distribute the processing of a full reindex job across multiple nodes.
This library makes use of Apache Ignite, and specifically makes use of Ignite’s distributed org.apache.ignite.IgniteQueue, which
is a distributed java.util.concurrent.BlockingQueue. We also make use of distributed java.util.concurrent.locks.Lock implementation
provided by Ignite. Finally, we make use of Ignite’s distributed events, which trigger Spring events internally.
As a result, the interaction with Ignite, for the most part, is via APIs that are native to Java and Spring, which is how the system works without Ignite.
Apache Ignite, by default, uses UDP to discover other Ignite nodes. In most cases, this is not an appropriate discovery mechanism. Apache Ignite does have other SPIs that can be used for discovery, including Apache ZooKeeper and cloud native mechanisms. See here for more information.
Adding this library to the classpath will activate the use of Apache Ignite for distributed (multi-machine) indexing. As mentioned, by default, UDP will be used for node discovery. Add a Spring Bean to override the configuration of Ignite:
// This example shows how you might configure ZooKeeper as an Ignite discovery mechanism:
@Bean
public IgniteConfiguration searchReindexerIgniteConfiguration(
IgniteIndexerProperties igniteIndexerProperties) {
ZookeeperDiscoverySpi zkDiscoverySpi = new ZookeeperDiscoverySpi();
zkDiscoverySpi.setZkConnectionString("zkHost1:2181,zkHost2:2181,zkHost3:2181");
zkDiscoverySpi.setSessionTimeout(30000);
zkDiscoverySpi.setZkRootPath("/broadleaf/ignite");
zkDiscoverySpi.setJoinTimeout(10000);
IgniteConfiguration ic = new IgniteConfiguration();
ic.setDiscoverySpi(zkDiscoverySpi);
HashMap<String, String> attrs = new HashMap<>();
attrs.put(igniteIndexerProperties.getRoleKey(), igniteIndexerProperties.getRoleName());
ic.setUserAttributes(attrs);
ic.setClientMode(false);
ic.setGridLogger(new Slf4jLogger());
return ic;
}In the above example, Apache Ignite will be configured on each Indexer node and will use Apache ZooKeeper as a discovery mechanism. ZooKeeper is used by Apache Solr and Apache Kafka, both of which are used, by default, by Broadleaf. As a result, you may choose to re-use a ZooKeeper cluster for each of these purposes.
This library provides Search Engine-agnostic components to aid in event handling and state management of (re)index jobs. This component also provides database integration to allow for job details and job metadata to be stored and retrieved. Additionally, this library provides facilities for responding to (re)index events.
This library provides Search Engine-agnostic components to define an Order, according to what needs to be indexed and searched.
This library, generally, provides components for triggering or responding to events to (re)index Order data. These components include message listeners, process launchers, and other components to fetch Order data, queue the order data, build the documents to be indexed, and write to the index. This library and its components are Search Engine-agnostic.
This library provides the Spring Configuration and a REST endpoint (OrderSearchEndpoint) that can be used in a Search application.
This library contains light-weight provider-agnostic (Search Engine-agnostic) components including the projection domain for search-related metadata. For example, this library contains projection domain for the definition of metadata for Fields, Variants, Redirects, Type Ahead, and Suggestions, that are common to search engines. These are database agnostic as well as search engine agnostic. Additionally, this library contains exceptions and high-level APIs, including:
SearchProvider
ReindexProvider
This library contains provider-agnostic (Search Engine-agnostic) components and APIs to allow us to integrate with a
search provider such as Solr. These components are provider-agnostic because they do not depend on Solr or any other
search engine. This library defines a database domain for the definition of metadata for Fields, Variants, Redirects, Type Ahead, and Suggestions,
that are common to search engines. It also provides Spring Data repositories for managing search metadata. Services APIs such as
SearchService, TypeAheadService, SearchRedirectService are also defined, as are their default implementations.
This library provides Apache Solr-specific components for interacting with Solr. For example, this library includes things like:
SolrAdminProvider - Provides APIs for interacting with basic administrative features in Solr like re-aliasing Solr collections
SolrCollectionResolver - Provides APIs for determining the correct foreground or background collection name for a given Indexable type
SolrIndexProvider - Extension of ReindexProvider, adding additional functionality specific to Solr, including APIs for commit logic
SolrProvider - A simple API to retrieve a SolrJ SolrClient (typically an instance of CloudSolrClient)
Various default implementations of these interfaces to allow for interaction with Solr
This library provides a number of Apache Solr-specific components for contributing to the creation of Solr documents. Specifically, these components add fields to documents for discrimination in Broadleaf multi-tenant Tracking capabilities. For example,
ApplicationTrackableSolrDocumentBuilderContributor - Application-tracked documents
CatalogTrackableSolrDocumentBuilderContributor - Catalog-tracked documents
CustomerContextTrackableSolrDocumentBuilderContributor - Customer Context-tracked documents
SandboxTrackableSolrDocumentBuilderContributor - Sandbox-tracked documents
TenantTrackableSolrDocumentBuilderContributor - Tenant-tracked documents
TranslationSolrDocumentBuilderContributor - Documents that include i18n translated values
For details on how the translations are contributed, see the documentation for indexing translations.
This library provides Apache Solr-specific functionality for (re)indexing. This includes:
A Solr-specific implementation of com.broadleafcommerce.search.index.core.service.ReindexService
Event Listeners specific to Solr-related indexing
DefaultSolrDocumentBuilder that can build a SolrInputDocument from an Indexable and a list of FieldDefinitions
This library provides Apache Solr-specific functionality to assist with Search capabilities. For example, this library contains components such as QueryBuilders,
QueryContributors, TypeAhead processors, etc. These components are required when using Apache Solr as the back-end Search Engine.
This library provides the most concrete implementation of an Indexer to index Catalog data in Solr. This makes use of many of the libraries above to compose a complete concrete implementation.
This library makes use of many of the libraries above to compose a complete, concrete implementation of a Search Service for Catalog data against a Solr index. This library also provides SQL to pre-load Field Definitions used to construct documents to index and queries for searching.
This library provides the most concrete implementation of an Indexer to index Customer data in Solr. This makes use of many of the libraries above to compose a complete concrete implementation.
This library makes use of many of the libraries above to compose a complete, concrete implementation of a Search Service for Customer data against a Solr index. This library also provides SQL to pre-load Field Definitions used to construct documents to index and queries for searching.
This library provides the most concrete implementation of an Indexer to index Order data in Solr. This makes use of many of the libraries above to compose a complete concrete implementation.
This library makes use of many of the libraries above to compose a complete, concrete implementation of a Search Service for Order data against a Solr index. This library also provides SQL to pre-load Field Definitions used to construct documents to index and queries for searching.