
- v1.0.0-latest-prod
The Broadleaf Microservices Architecture not only provides implementers the flexibility to start simple, but also provides you the power to scale when you need to. A big component to this revolves around the Flex Package Composition architecture described here: Deployment Flexibility
We’ve put Broadleaf to the test simulating real world commerce scenarios from flows demonstrating industry standard Black Friday and Cyber Monday metrics to more extreme transactional use cases in the "thousands per second". We highly recommend digesting the information in our scalability white paper that describes our approach to achieving these results. We also recommend using this report as a baseline guide for infrastructure sizing and planning exercises.
Sign up to download our scalability white paper here: https://www.broadleafcommerce.com/scalability-report
Broadleaf has the ability to scale horizontally with microservices and is ideal for cloud-based environments, especially those leveraging Kubernetes.
We provide a lot of support for deployments on a Kubernetes cluster including baseline sizing guides and comparative performance testing results on different sized clusters.
|
Tip
|
The scalability white paper introduces a naming scheme that combines application
and infrastructure sizing into a shortened name like BS3 or GL5 for easy reference. You will see these terms used in our documentation and references.
|
Given that many of our clients use our framework to support a variety of different commerce needs, the variety of services being used differ from implementation to implementation, and the level of customizations and external integrations can highly influence performance metrics - it’s not feasible for us to give a "one-size-fits-all" sizing or tuning recommendation that will work for everybody. With that said, we do have general guidance and strategies that should aid when conducting your own performance and load tests.
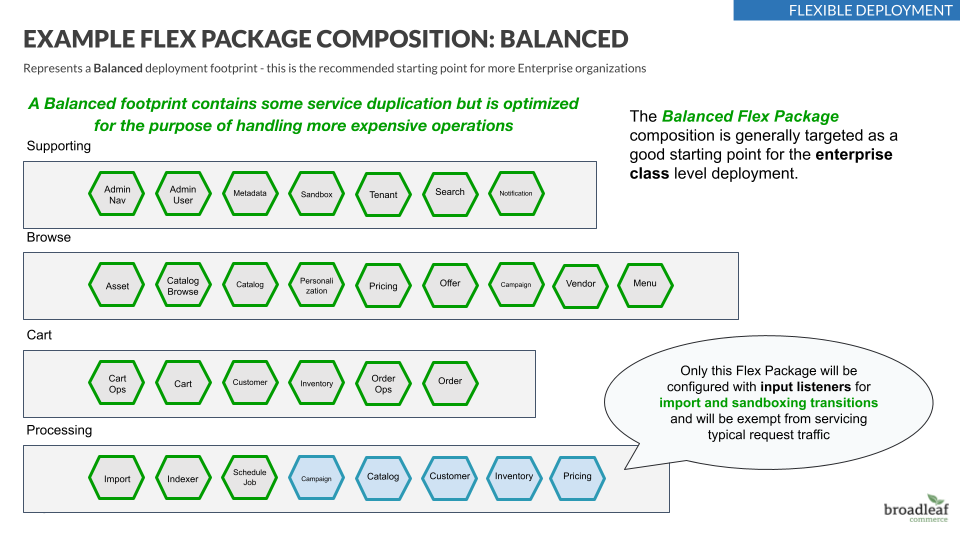
We recommend that most Enterprise installations start off with the Balanced Flex Package composition. Please read the section below for more guidelines on setting up a Balanced configuration. When your needs begin to outgrow this configuration, see our tutorial on Flex Package mobility.
Determine your initial hardware footprint based on the particular throughput you expect to achieve for your implementation. Use Appendix B in the Scalability White Paper as a reference for Node Pool sizing and and Database specifications.
The performance of the system will be most sensitive to adjustments in CPU core request configuration
In general, we’ve found that the most efficient sizing when using the Balanced Flex Package utilizes 3000m for Cart Flex Package replicas, and 2000m for Browse Flex Package replicas.
When determining how to optimize resources in your cluster based on your implementation you will want to conduct your own load test. When doing this, start with liberal node sizes and do not define pod constraints to begin with. Run the load test and review kubectl top pod results to see where resources are naturally allocated. Use this as your guideline and use replicaCount to scale to meet your objective and create baseline constraints.
When your looking to scale the Node Pool (e.g. going from a BM3 to a BM5 configuration), here are two strategies to consider:
Scale the nodes in your current cluster (just increase the node count).
Vertically scale the existing nodes (e.g. 4 CPU to 8 CPU) - which in most cases will require a new node pool to be provisioned with the new node sizes. Both node pools can be used or you can move all traffic to the new node pool using native Kubernetes facilities.
|
Tip
|
Much more detail around these recommendations can be found in the Scalability White Paper, particularly in Appendix F - Technical Recommendations
|
Balanced Flex Package Composition GuidelinesAs mentioned before, we recommend that most Enterprise installations start off with the Balanced Flex Package composition. This composition represents a curated commerce segmentation
grouping services logically together that will typically support most commerce deployment needs.
For example:
Browse Flex Package: contain services that primarily support customer facing storefront flows like
browsing, searching, product listing pages, and product detail pages. The idea being that
scaling these services that support high-request flows will be important for typical commerce implementations.
Cart Flex Package: contain more transactional-type services that facilitate flows like
"add to cart" and "checkout"
Supporting Flex Package: contains services that underpin and support a lot of the foundational
aspects across the different services
Processing Flex Package: this is unique in this composition as it has been segmented off to support
longer running background tasks (e.g. scheduled jobs, indexing, etc…). It is architected to contain some "duplicate" services so that this does not have to create "external pressure" on other services. For example, it’s detrimental to have long-running tasks that cause resource constraints on your
browse level services that can impact overall site experience and conversions.
Processing Flex Package GuidelinesGenerally, for the Processing Flex Package, it is primarily structured as a message-driven paradigm for longer running jobs. It will process messages as fast as it can with the resources provided. There is an expectation of a queue here. I.e., processing pods should be configured to be very lenient about response times and CPU utilization - for example, hitting 90% while indexing processes are running would be normal and scaling would not necessarily benefit the operation and definitely should not be considered a sign that the pod is "bad" and needs to be recycled.
Given the behavior, it’s not optimal to configure horizontal autoscaling based on CPU - it’s not the same as a HTTP request server handling a bunch of user requests. In general, it does not make sense to auto-scale the PROCESSING flex package horizontally. Generally a few replicas (for HA purposes) for the processing flex package would be sufficient for many implementations.